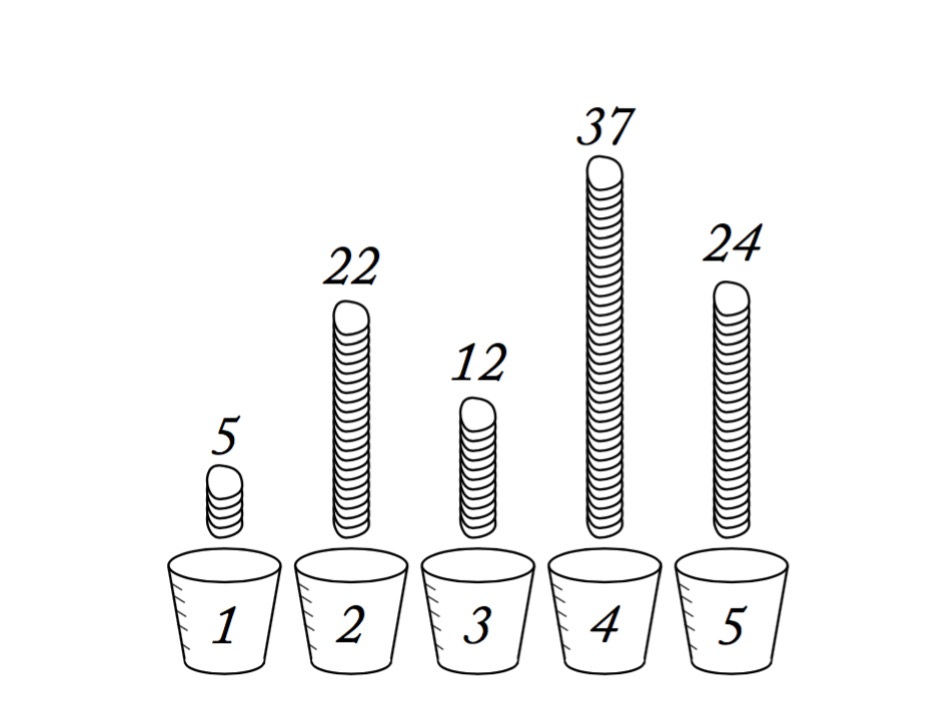
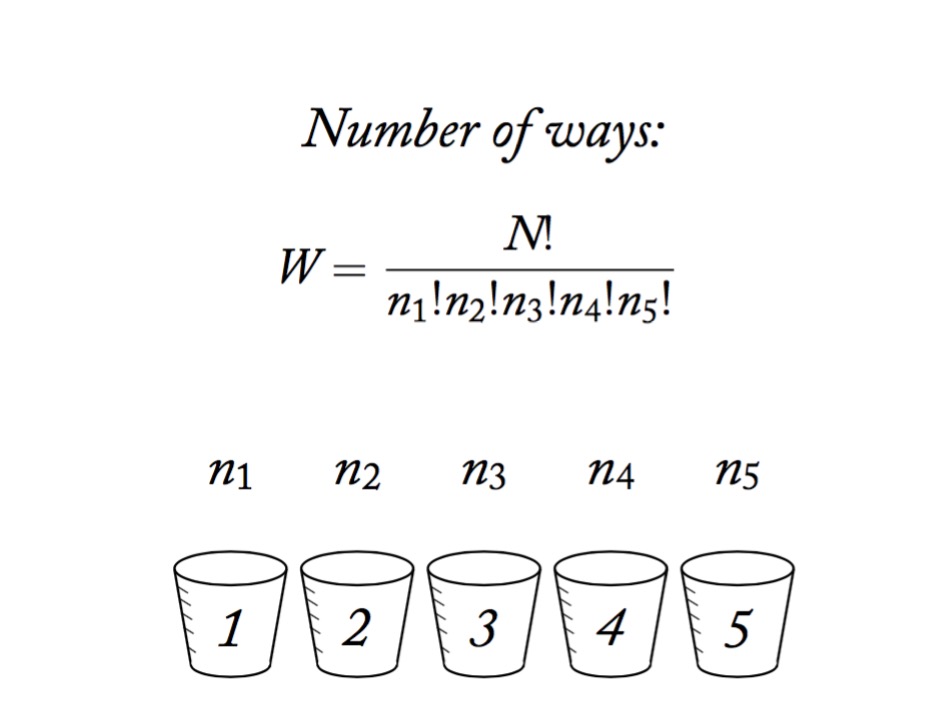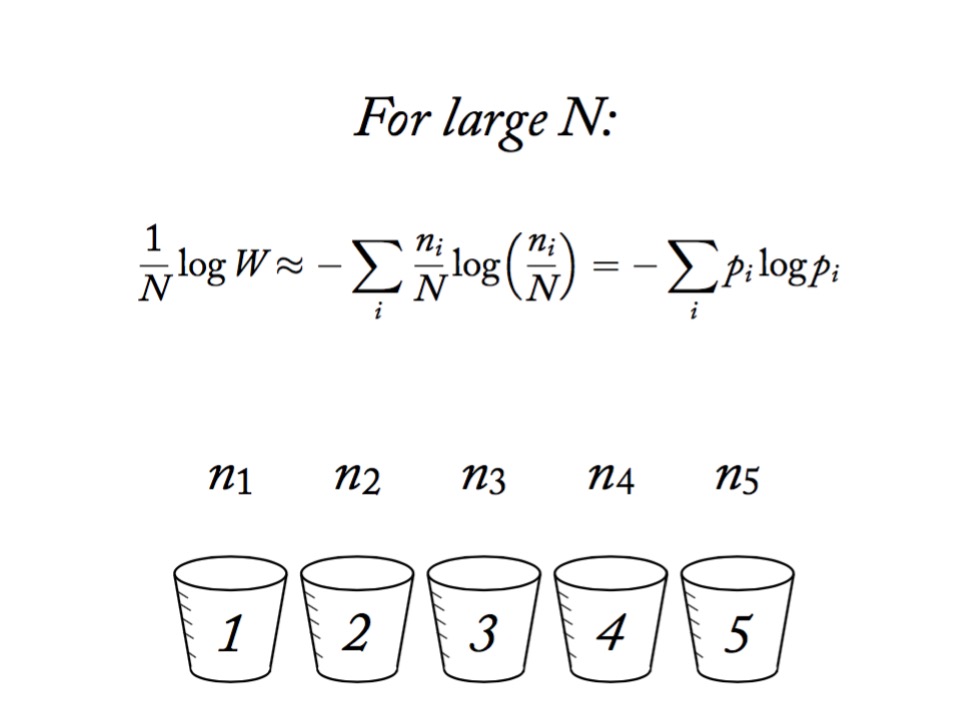Data Generating Process with identity link
f(\(\mu_i) = \alpha + \beta_1 x1_i + \beta_2 x2_i + ...\)
Priors:
…
A Generalized Linear Model
Likelihood: \(y_i \sim D(\theta_i, ...)\)
Data Generating Process with identity link
f(\(\theta_i) = \alpha + \beta_1 x1_i + \beta_2 x2_i + ...\)
Priors:
…
A Generalized Outline
Why use GLMs? An Intro to Entropy
Logistic Regression
Poisson Regression
Poisson -> Multinomial
What is Maximum Entropy?
Maximum Entropy Principle
The distribution that can happen the most ways is also the distribution with the biggest information entropy. The distribution with the biggest entropy is the most conservative distribution that obeys its constraints.
-McElreath 2017
Why are we thinking about MaxEnt?
MaxEnt distributions have the widest spread - conservative
Nature tends to favor maximum entropy distributions
It’s just natural probability
The foundation of Generalized Linear Model Distributions
Leads to useful distributions once we impose constraints
McElreath 2016
McElreath 2016
McElreath 2016
McElreath 2016
McElreath 2016
McElreath 2016
McElreath 2016
McElreath 2016
Information Entropy
\[H(p) = - \sum p_i log \, p_i\]
Measure of uncertainty
If more events possible, it increases
Nature finds the distribution with the largest entropy, given constraints of distribution
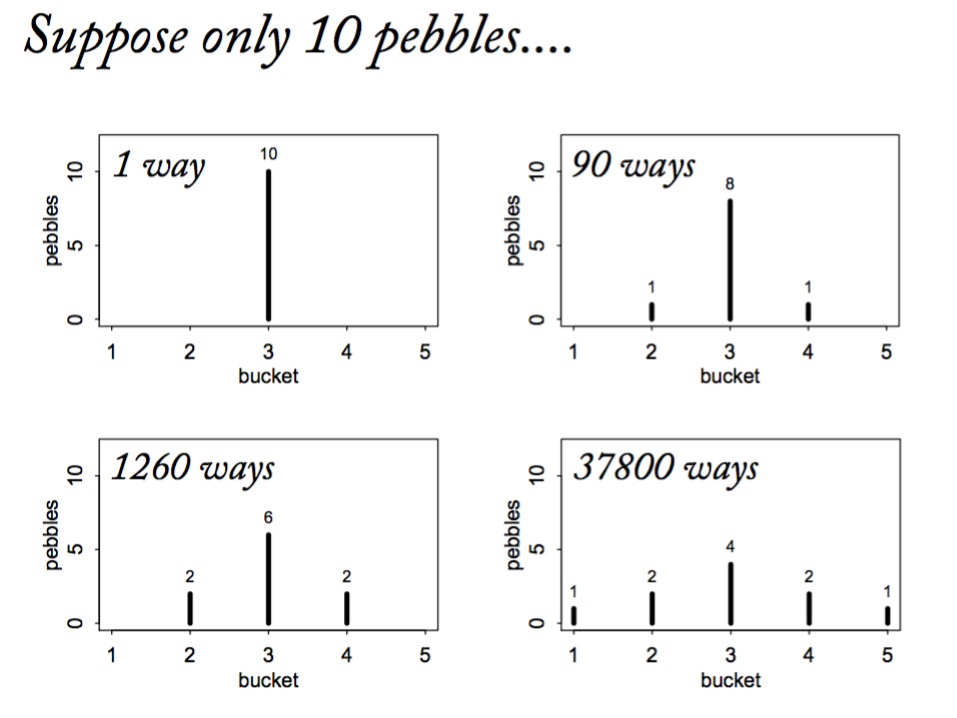
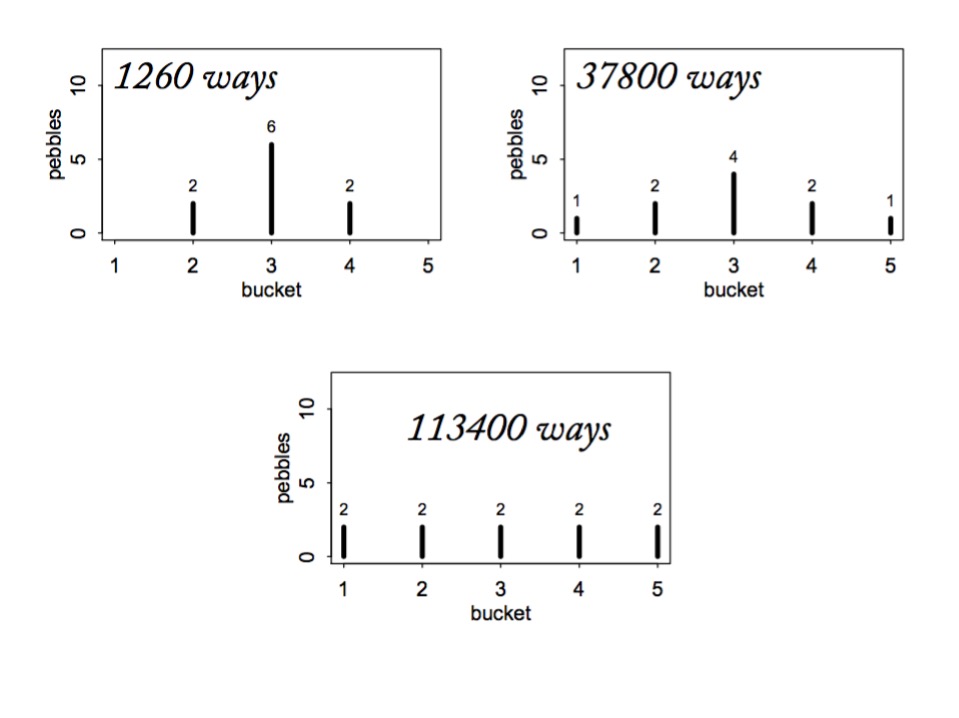
Maximum Entropy and Coin Flips
Let’s say you are flipping a fair (p=0.5) coin twice
What is the maximum entropy distribution of # Heads?
Possible Outcomes: TT, HT, TH, HH
which leads to 0, 1, 2 heads
Constraint is, with p=0.5, the average outcome is 1 heads
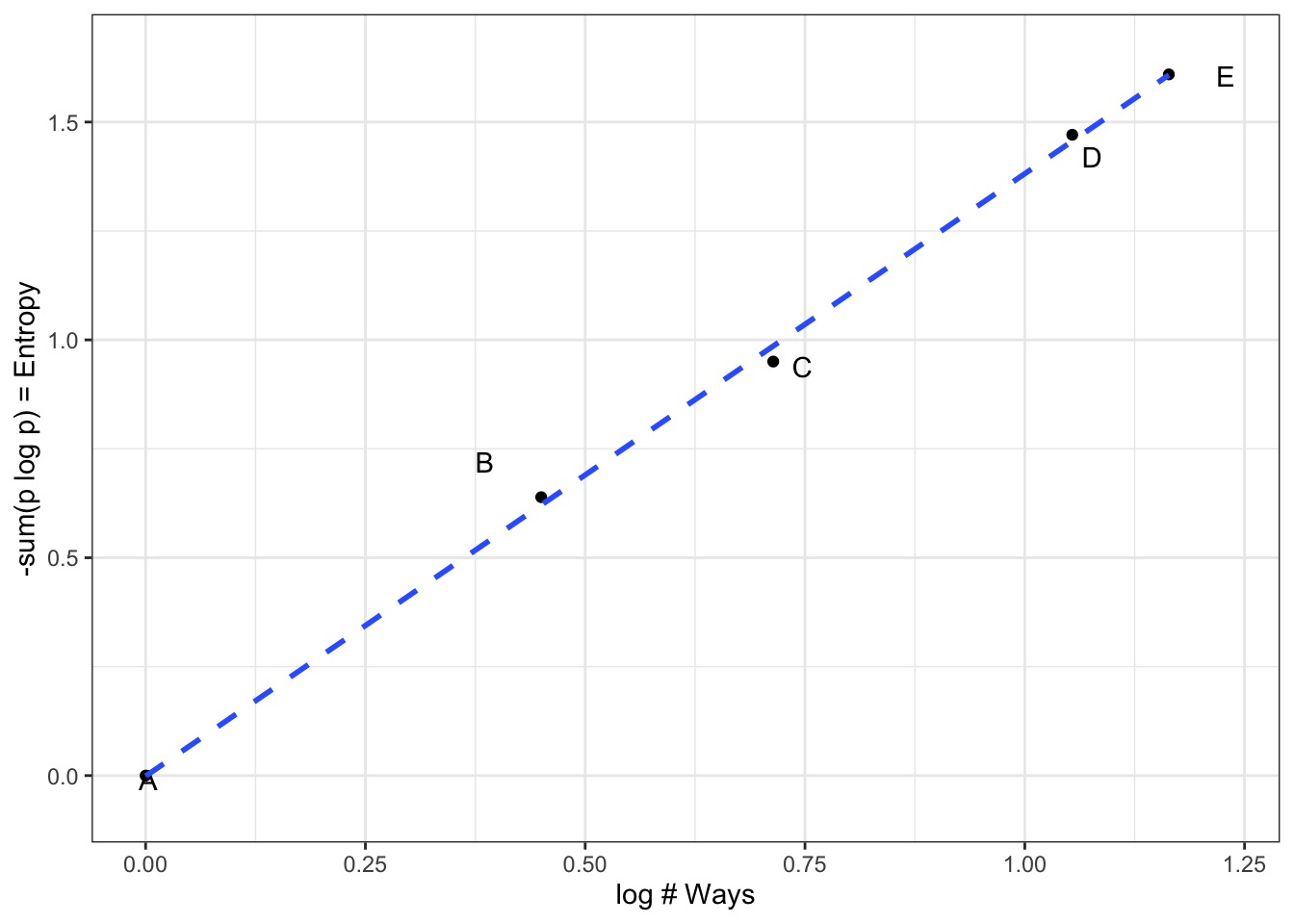
The Binomial Possibilities
TT = p2
HT = p(1-p)
TH = (1-p)p
HH = p2
But other distributions are possible
Let’s compare other distributions meeting constraint using Entropy
Remember, we must average 1 Heads, so,
sum(distribution * 0,1,1,2) = 1
\[H = - \sum{p_i log p_i}\]
Distribution
TT, HT, TH, HH
Entropy
Binomial
1/4, 1/4, 1/4, 1/4
1.386
Candiate 1
2/6, 1/6, 1/6, 2/6
1.33
Candiate 2
1/6, 2/6, 2/6, 1/6
1.33
Candiate 3
1/8, 1/2, 1/8, 2/8
1.213
Binomial wins!
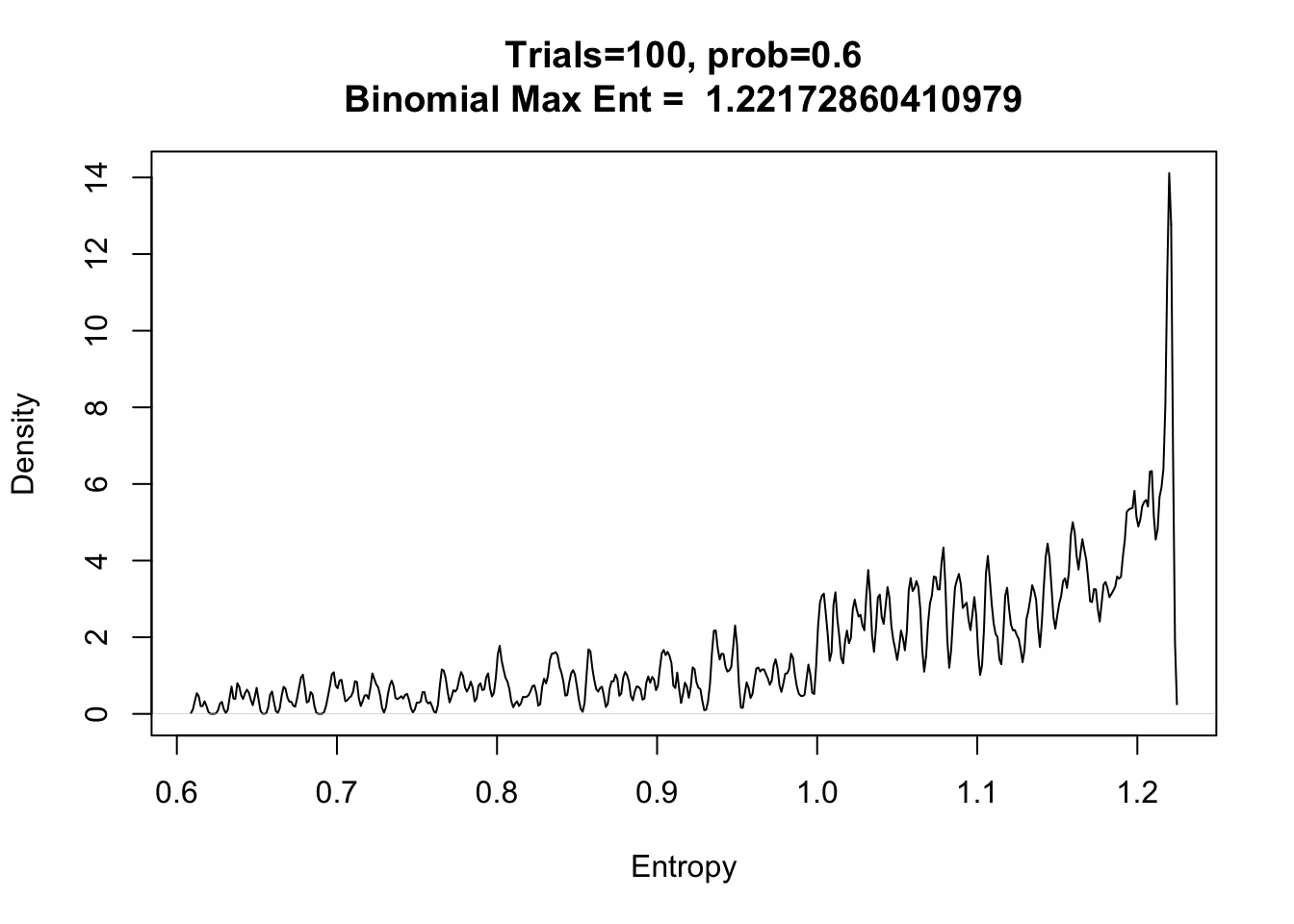
What about other p’s and draws?
Assume 2 draws, p=0.7, make 1000 simulated distributions
OK, what about the Gaussian?
Constraints: mean, finite variance, unbounded
Lots of possible distributions for normal processes
Flattest distribution given constraints: MaxEnt
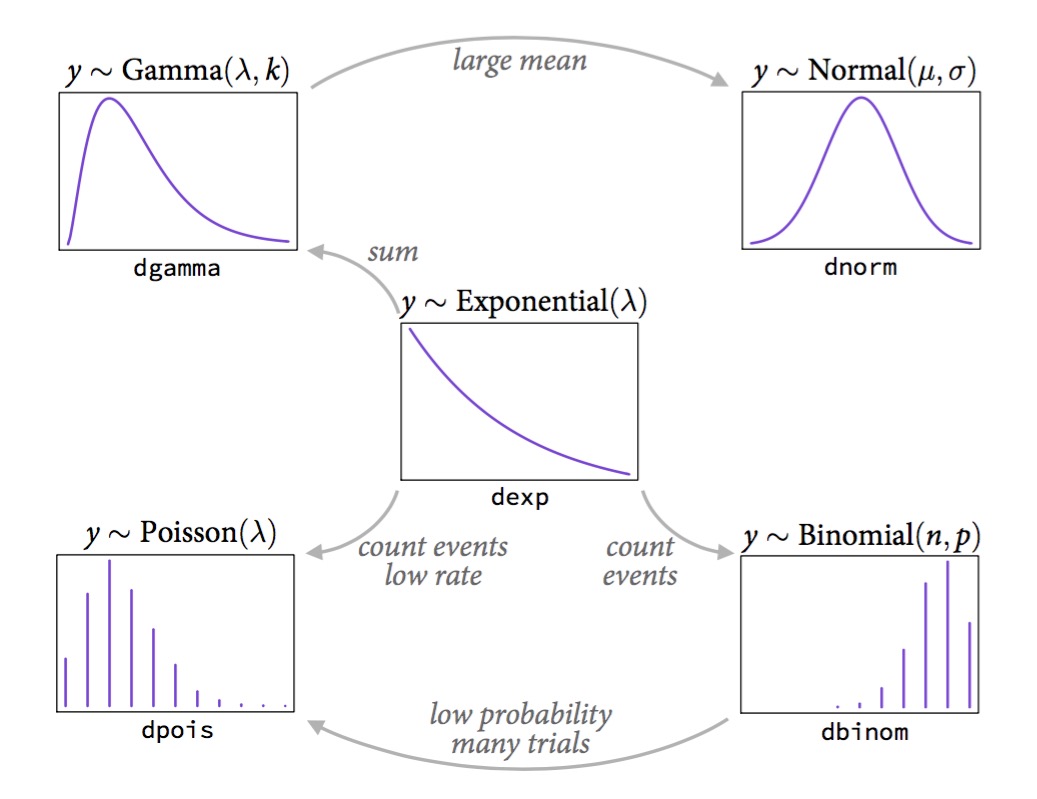
Maximum Entropy Distributions
Constraints
Maxent distribution
Real value in interval
Uniform
Real value, finite variance
Gaussian
Binary events, fixed probability
Binomial
Sum of binomials as n -> inf
Binomial
Non-negative real, has mean
Exponential
How to determine which non-normal distribution is right for you
Use previous table to determine
Bounded values: binomial, beta, Dirchlet
Counts: Poisson, multinomial, geometric
Distances and durations: Exponential, Gamma (survival or event history)
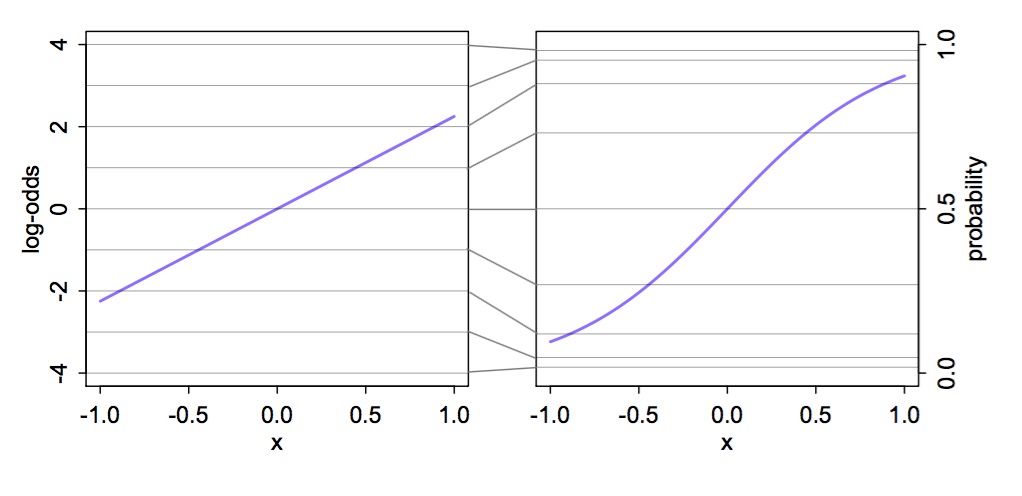
\(\frac{p_i}{1-p_i}\) is odds of something happening
\(\beta\) is change in log odds per one unit change in \(x_i\)
exp(\(\beta\)) is change in odds
Change in relative risk
\(p_i\) is absolute probability of something happening
logistic(\(\alpha + \beta x_i\)) = probability
To evaluate change in probability, choose two different \(x_i\) values
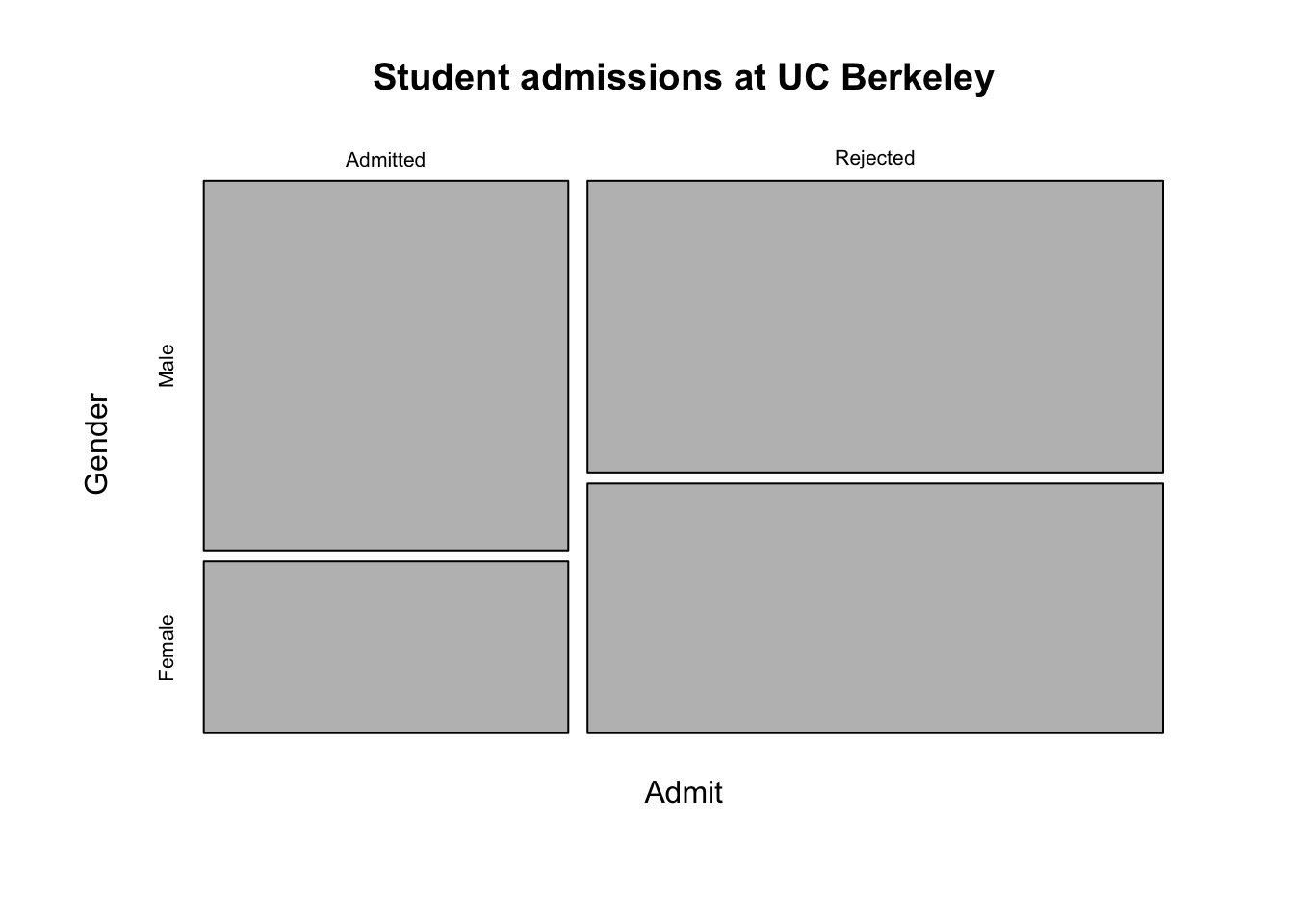
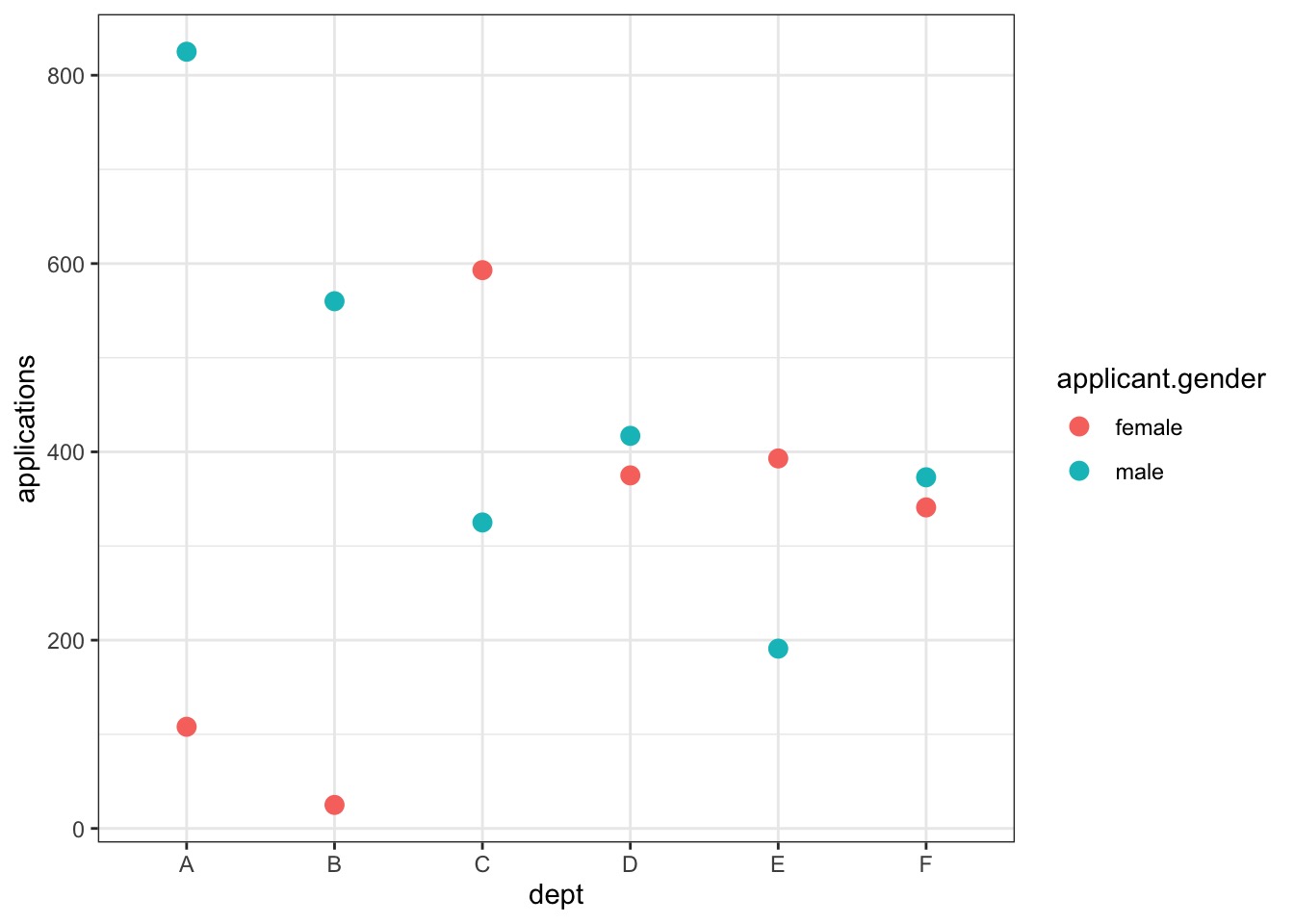
Binomial GLM in Action: Gender Discrimination in Graduate Admissions
Our data: Berkeley in 1973
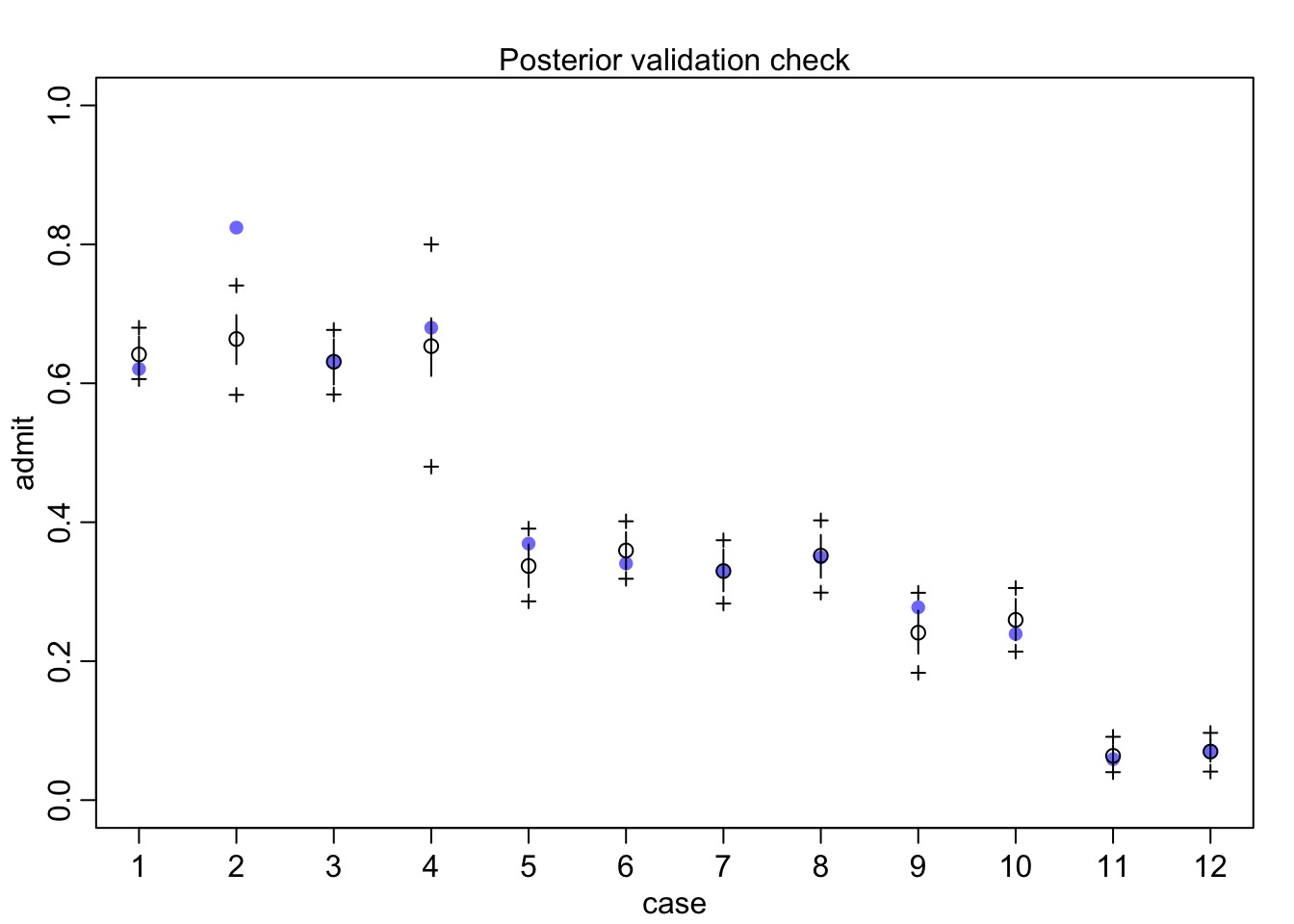
data(UCBadmit)head(UCBadmit)
dept applicant.gender admit reject applications
1 A male 512 313 825
2 A female 89 19 108
3 B male 353 207 560
4 B female 17 8 25
5 C male 120 205 325
6 C female 202 391 593
The Gender Gap
Gender
Admit Male Female
Admitted 1198 557
Rejected 1493 1278
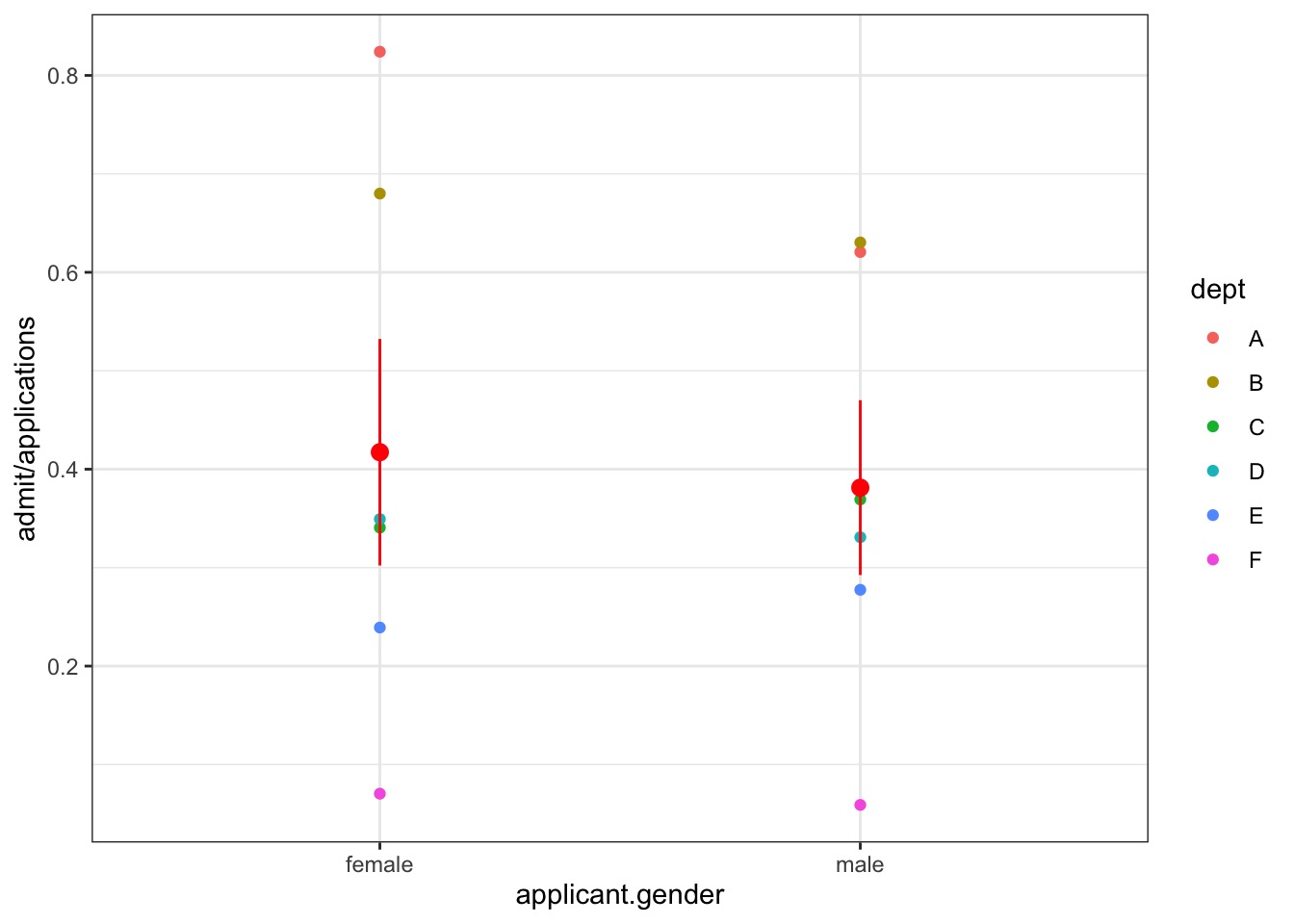
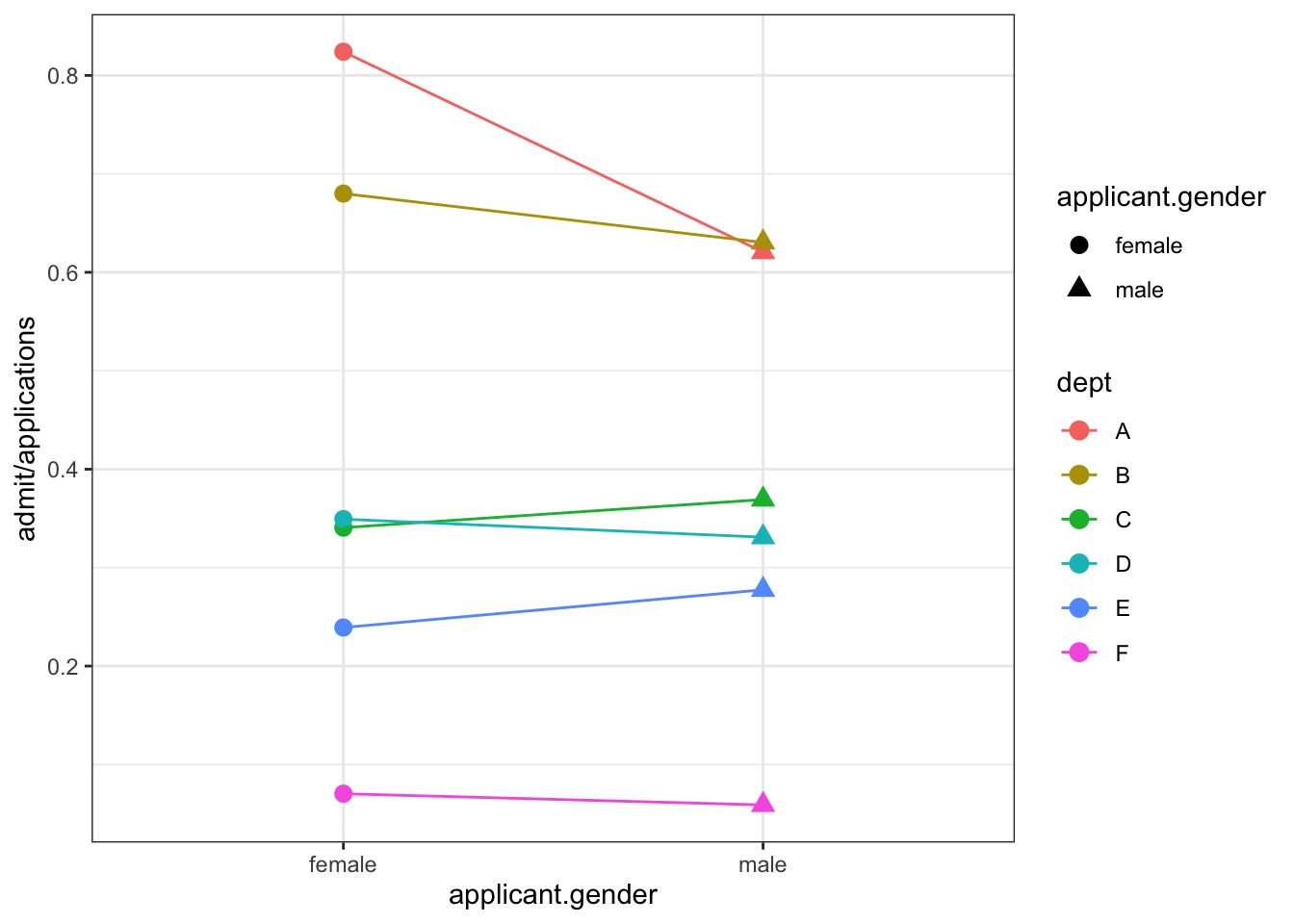
Doesn’t Look like a Gender Gap if we Factor In Department…
But Gender -> Department Applied To
Porportion Admitted by Department…
What model would you build?
dept applicant.gender admit reject applications
1 A male 512 313 825
2 A female 89 19 108
3 B male 353 207 560
4 B female 17 8 25
5 C male 120 205 325
6 C female 202 391 593
Mediation Model
Gender influences where you apply to. Department mediates gender to admission relationship.
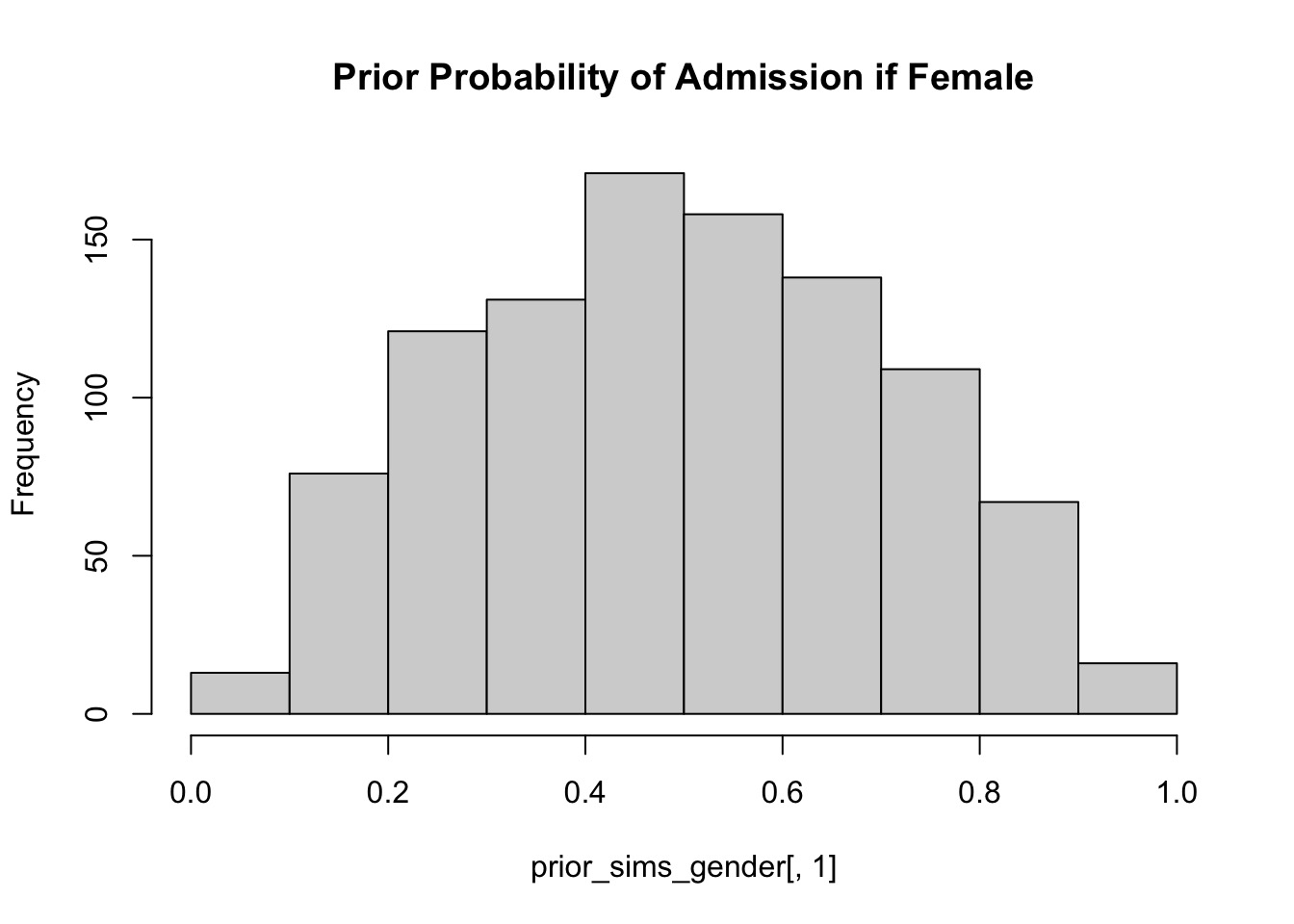
#Let's simulate some priors!prior_sims <-extract.prior(fit_gender)# prior sims of gender assuming average no effect of dept - 50:50prior_sims_gender <-inv_logit(prior_sims$a) hist(prior_sims_gender[,1], main ="Prior Probability of Admission if Female")
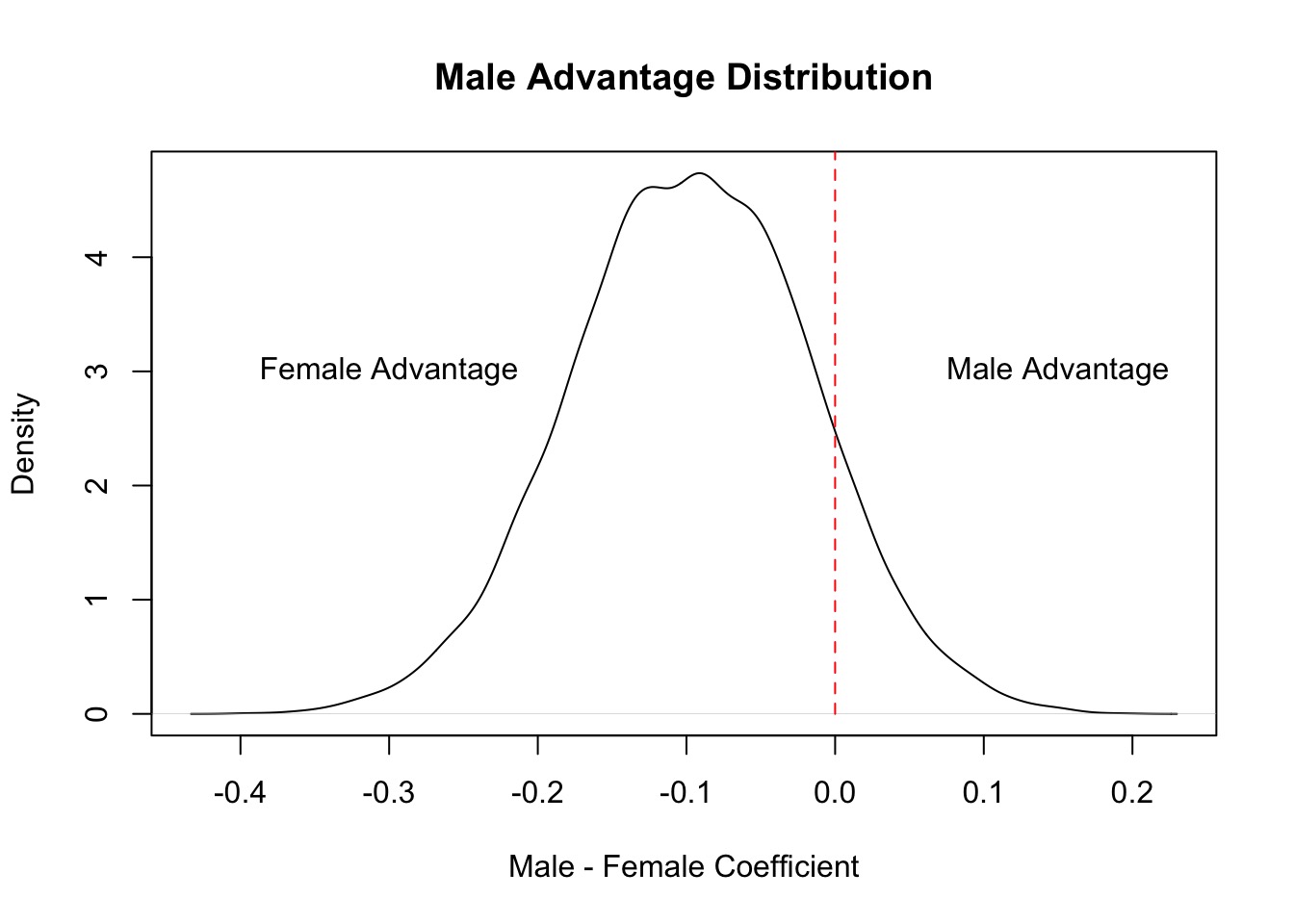
mean sd 10% 90% histogram
-0.09682634 0.08074047 -0.200614 0.006134635 ▁▁▁▂▅▇▇▅▂▁▁▁
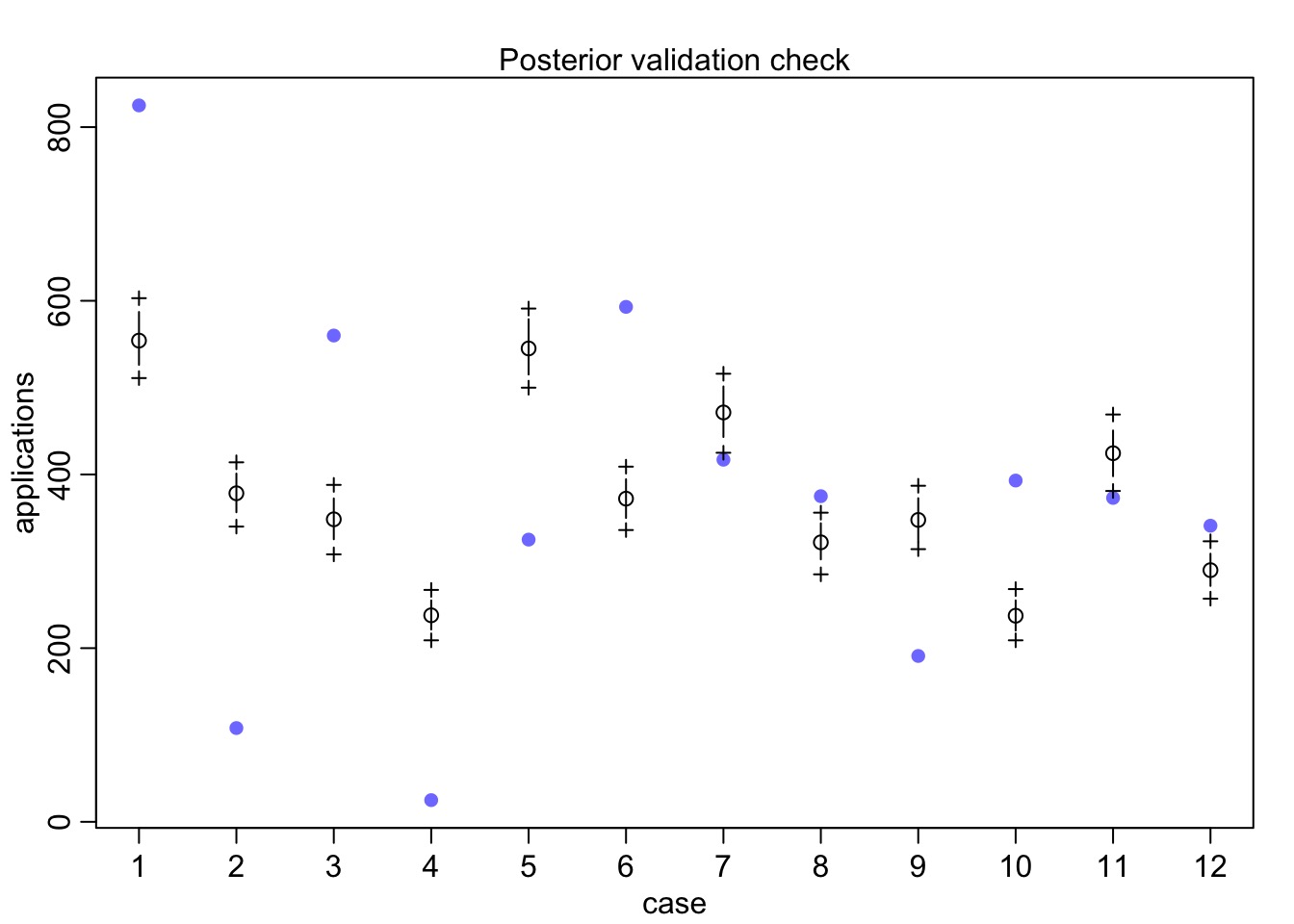
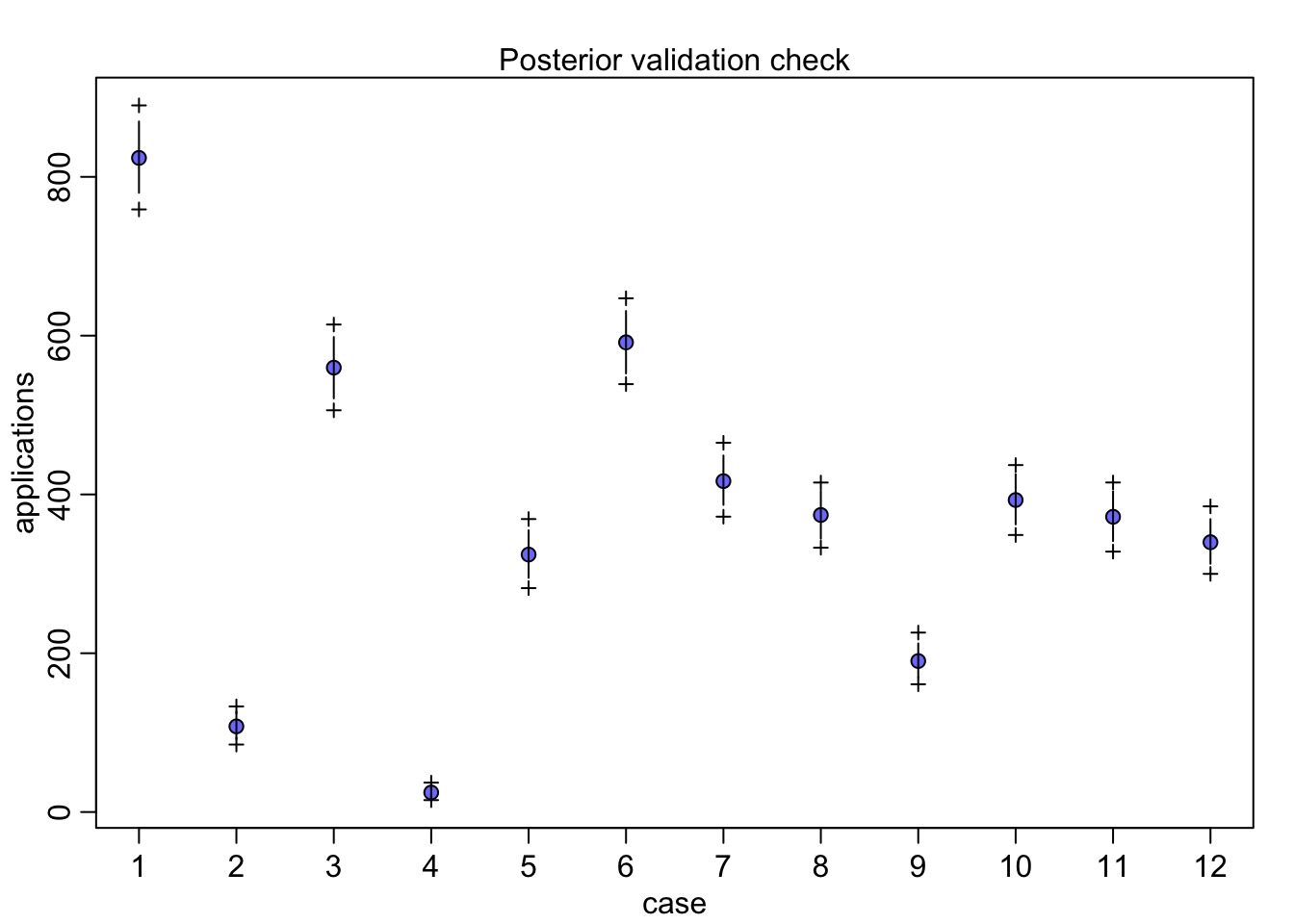
Does our Data Fall in Observations?
Quantile Residuals
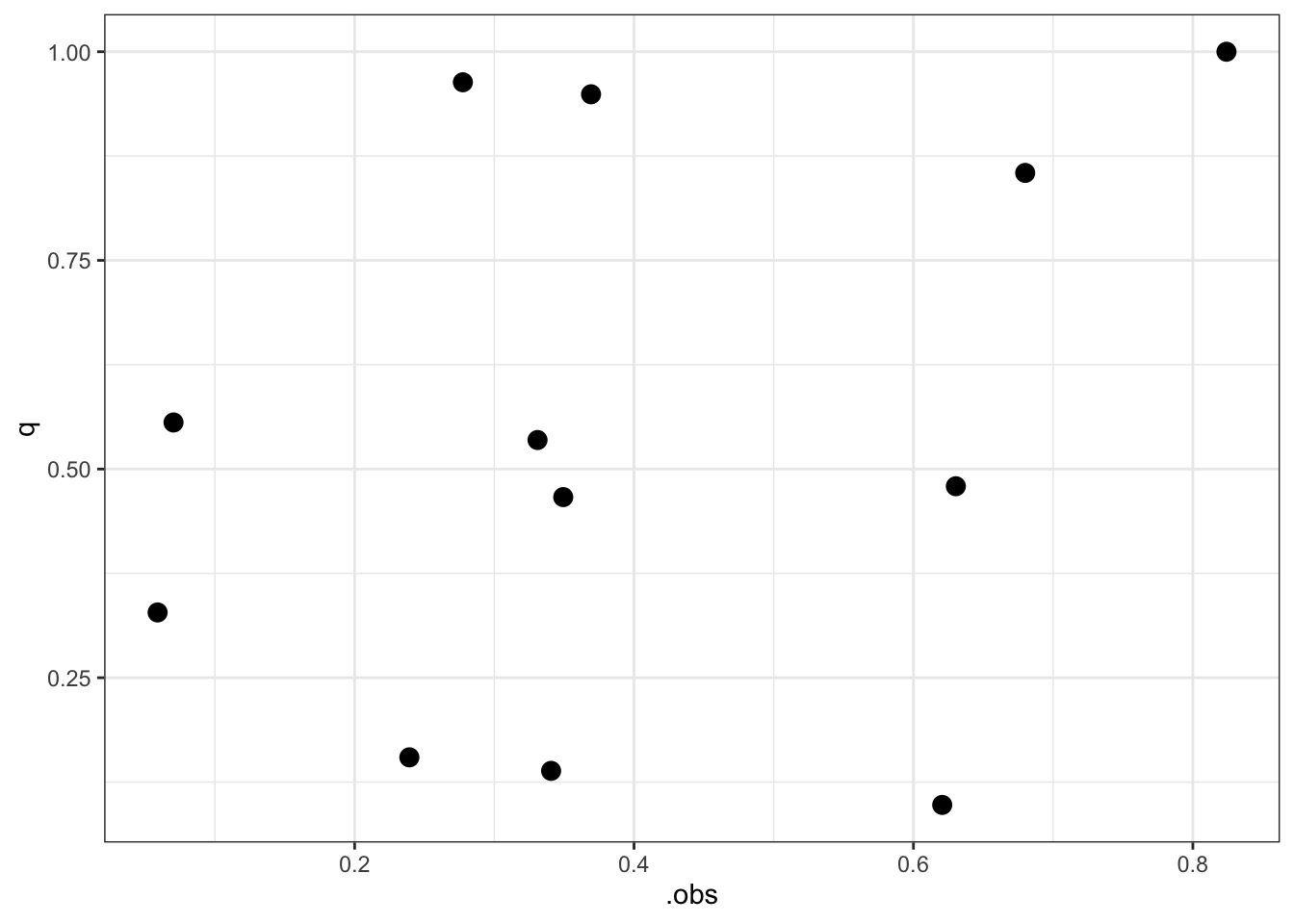
qpreds <-add_linpred_draws(UCBadmit, fit_gender) |>mutate(.obs = admit/applications) |>group_by(dept, applicant.gender) |># make an empirical dist of each linpred# then get quantile of resultsummarize(dist =list(ecdf(.linpred)),.obs = .obs[1],q = purrr::map_dbl(.obs[1], dist))
Quantile Residuals and Fits
ggplot(qpreds,aes(.obs, q)) +geom_point(size =3)
QQ Unif Check
gap::qqunif(qpreds$q, logscale=FALSE)
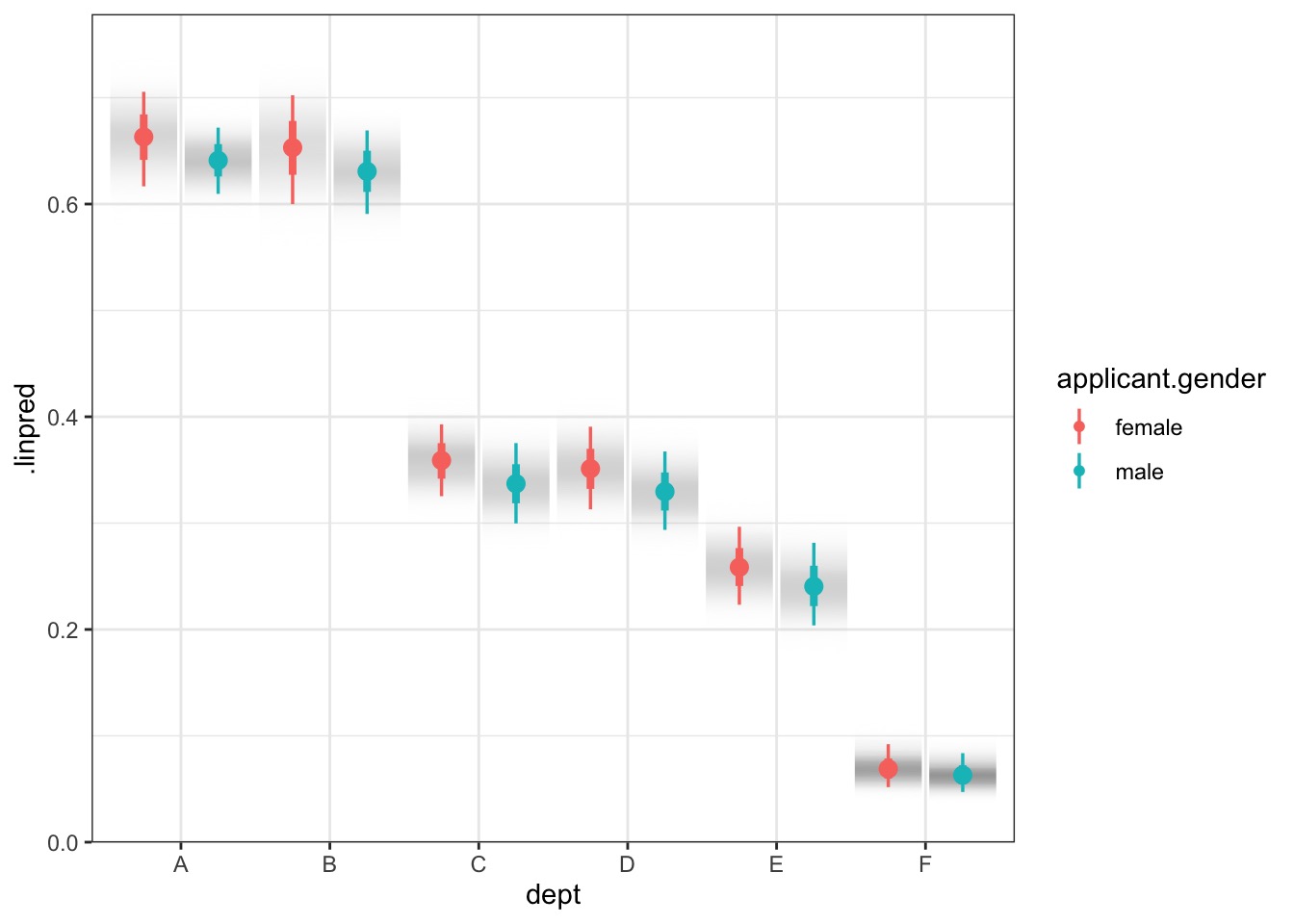
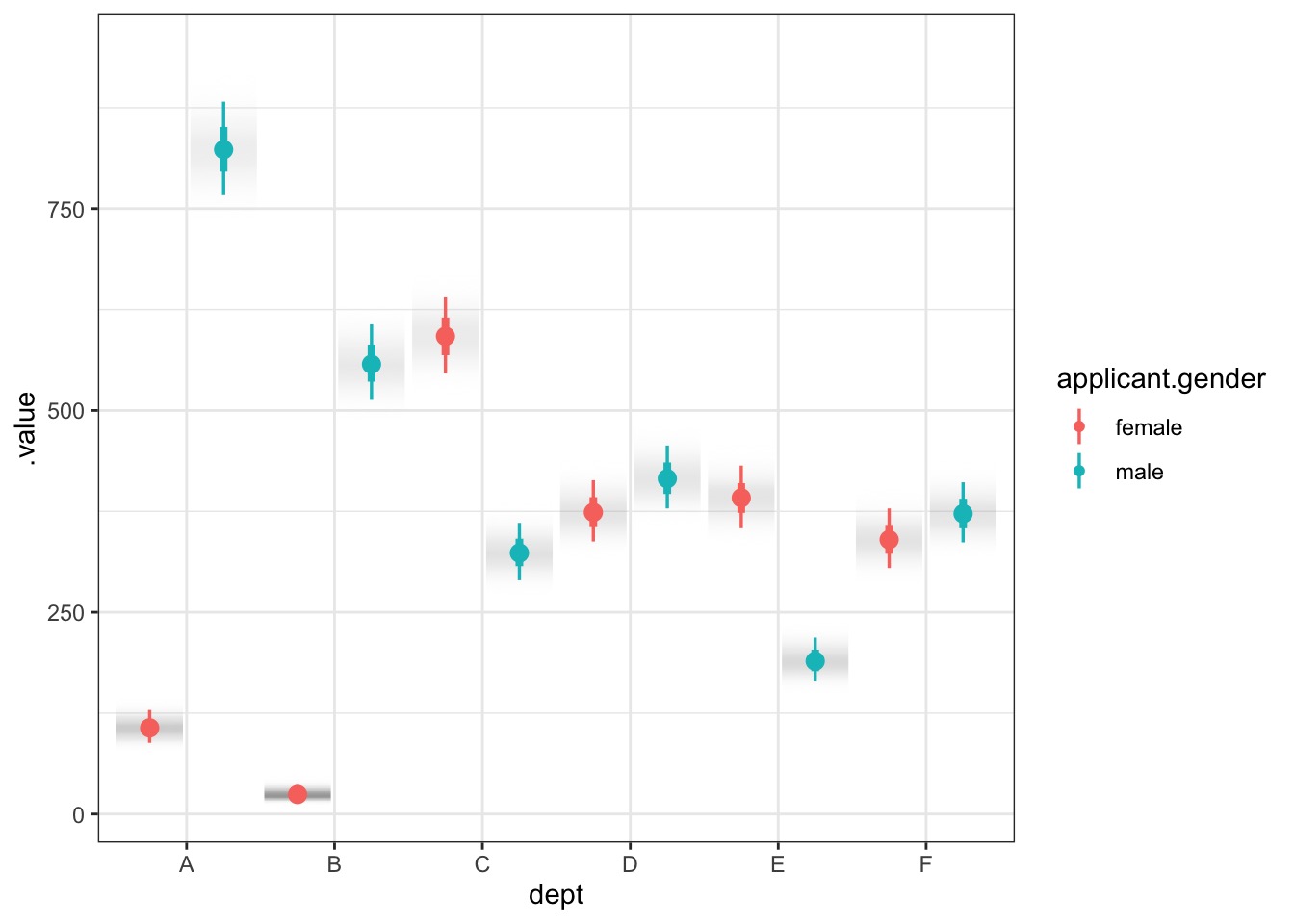
Model Vis with Tidybayes
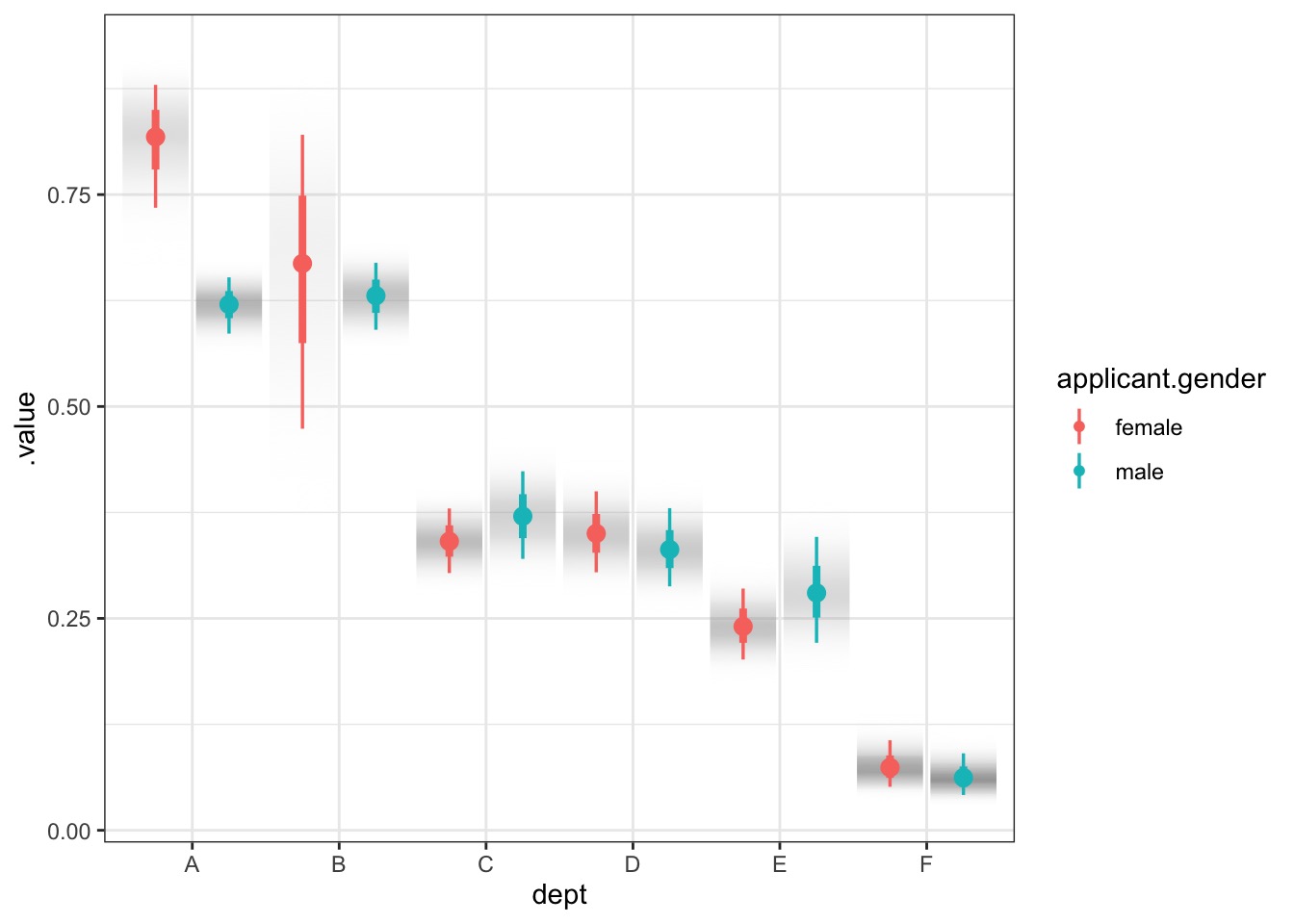
preds <-add_linpred_draws(UCBadmit, fit_gender)ggplot(preds, aes(x = dept, y = .linpred,group = applicant.gender, color = applicant.gender)) +stat_gradientinterval(position ="dodge")
Model Vis with Tidybayes
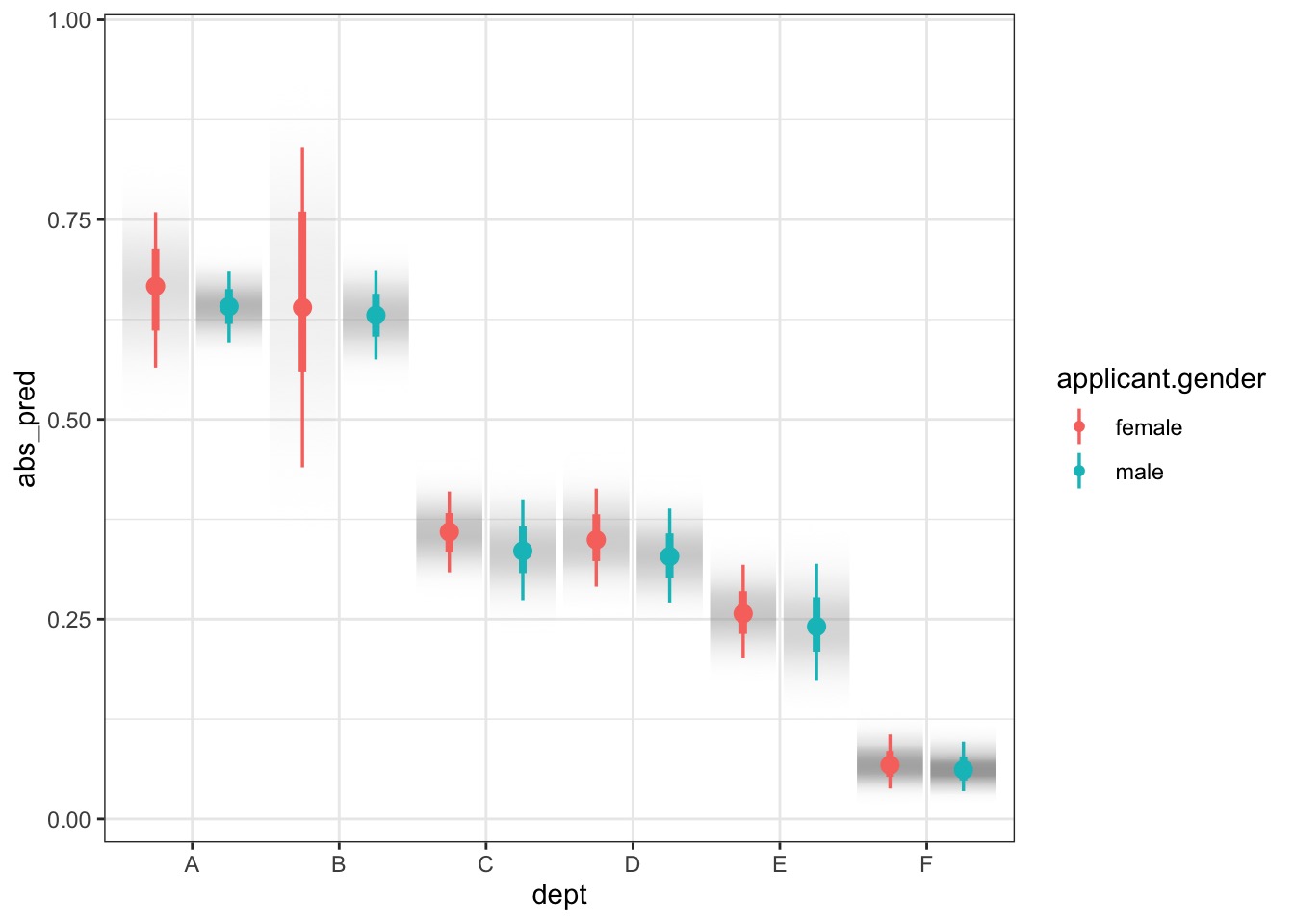
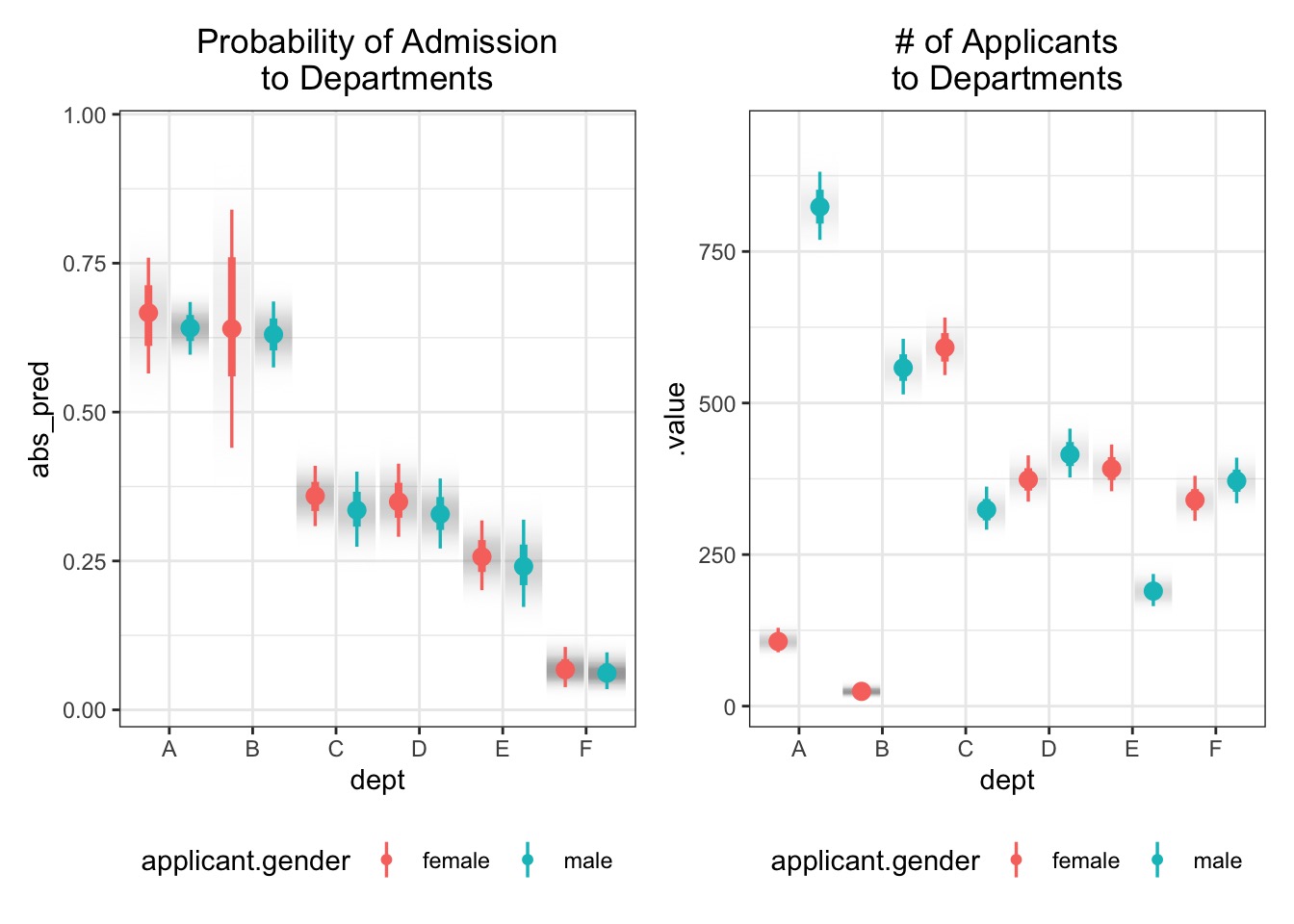
Prediction Intervals and Binomial GLMs
Of course, predictions are 1 or 0 for a straight binomial GLM.
But, more than just coefficient variability is at play
So, we simulate # of successes out of some # of attempts.
Can use this to generate prediction intervals
Prediction Model Vis with Tidybayes
preds_all <-add_predicted_draws(UCBadmit, fit_gender) |>mutate(abs_pred = .prediction/applications)ggplot(preds_all, aes(x = dept, y = abs_pred,group = applicant.gender, color = applicant.gender)) +stat_gradientinterval(position ="dodge")
Prediction Model Vis with Tidybayes
But what about this?
A Generalized Outline
Why use GLMs? An Intro to Entropy
Logistic Regression
Poisson Regression
Poisson -> Multinomial
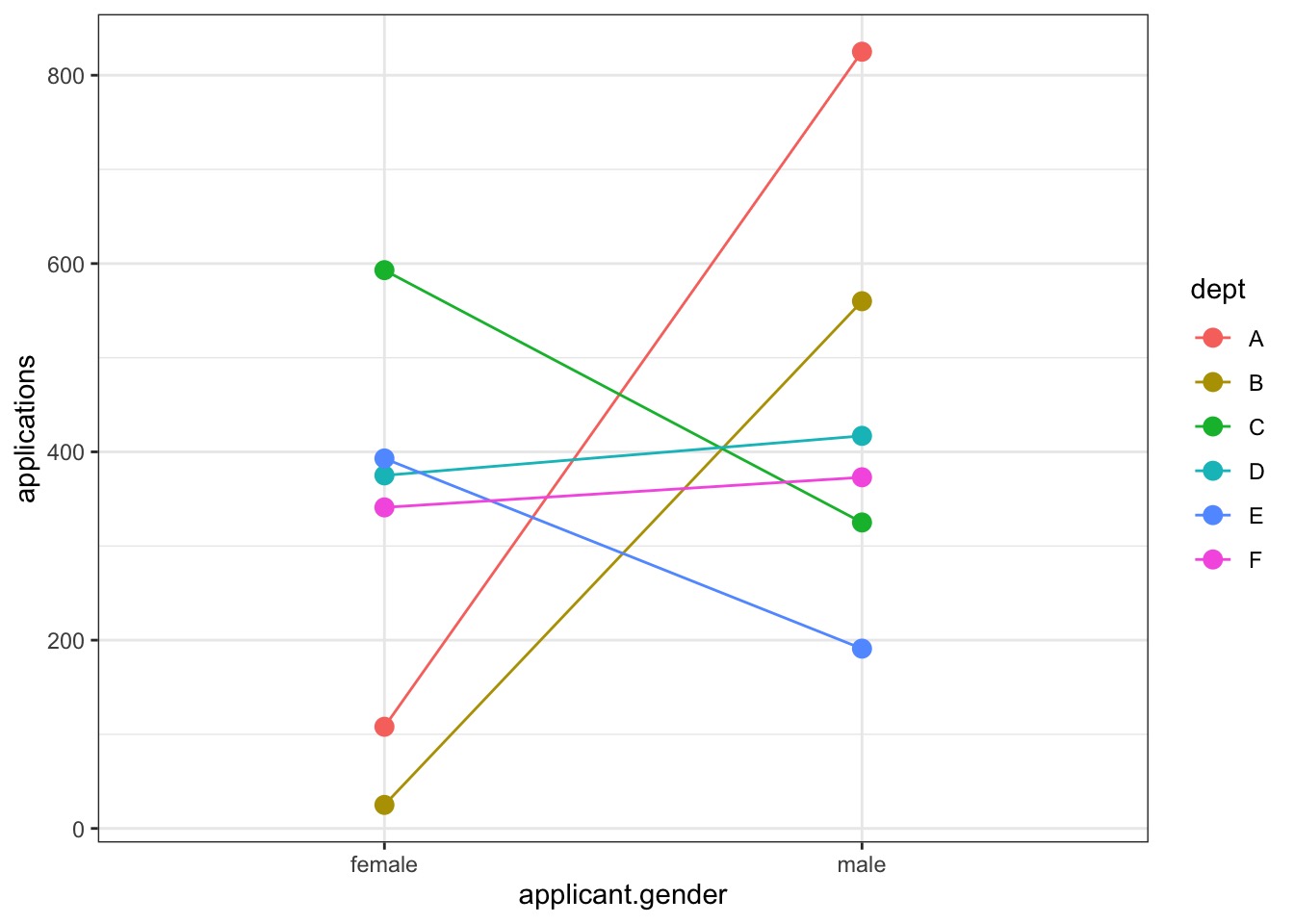
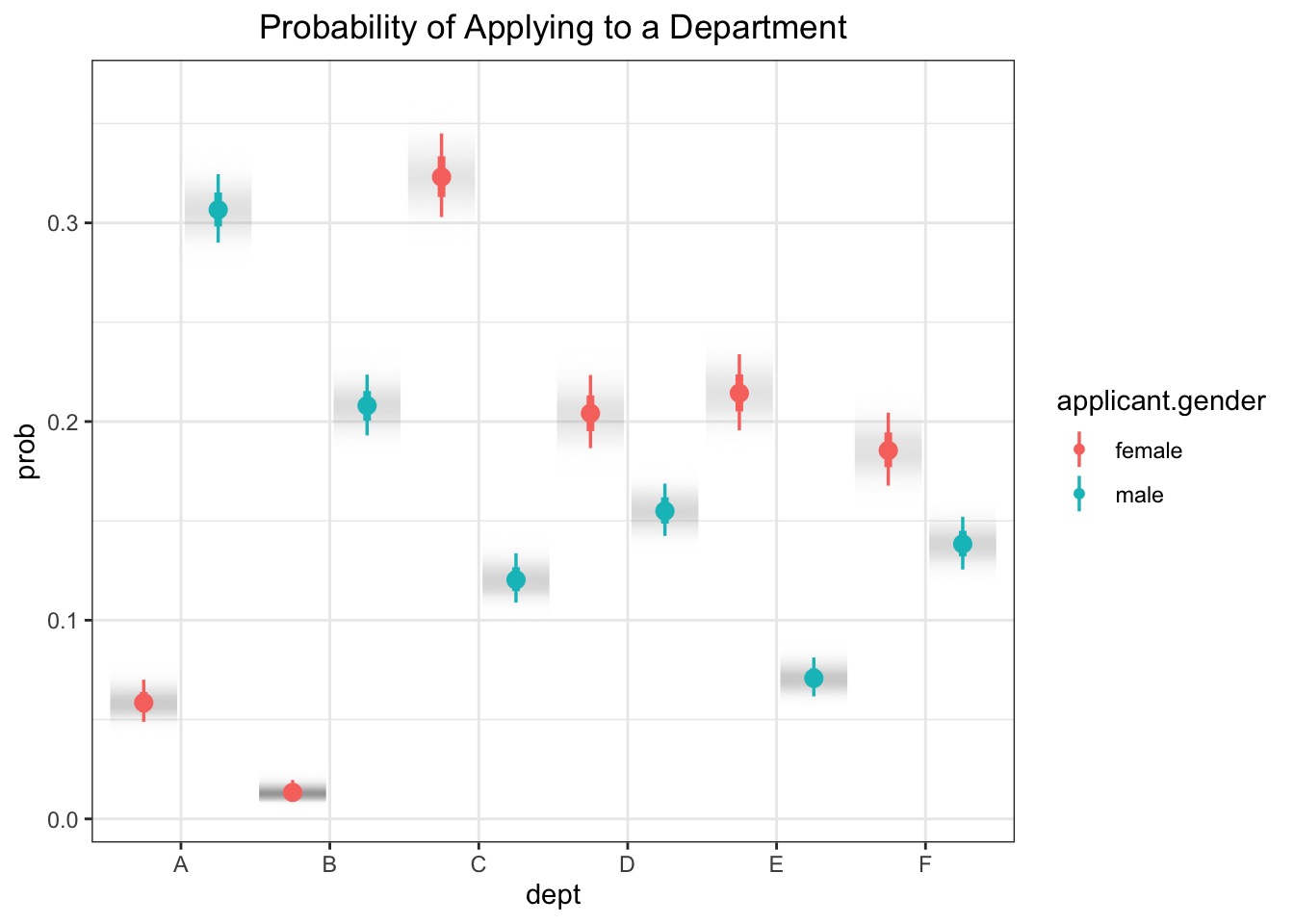
Disparities in Who Applied Where?
Modeling How Gender Influences Application
It could be just different departments get different #s.
It could be gender + department.
It could be differential application by department.
How to determine which non-normal distribution is right for you
Use previous table to determine
Bounded values: binomial, beta, Dirchlet
Counts: Poisson, multinomial, geometric
Distances and durations: Exponential, Gamma (survival or event history)
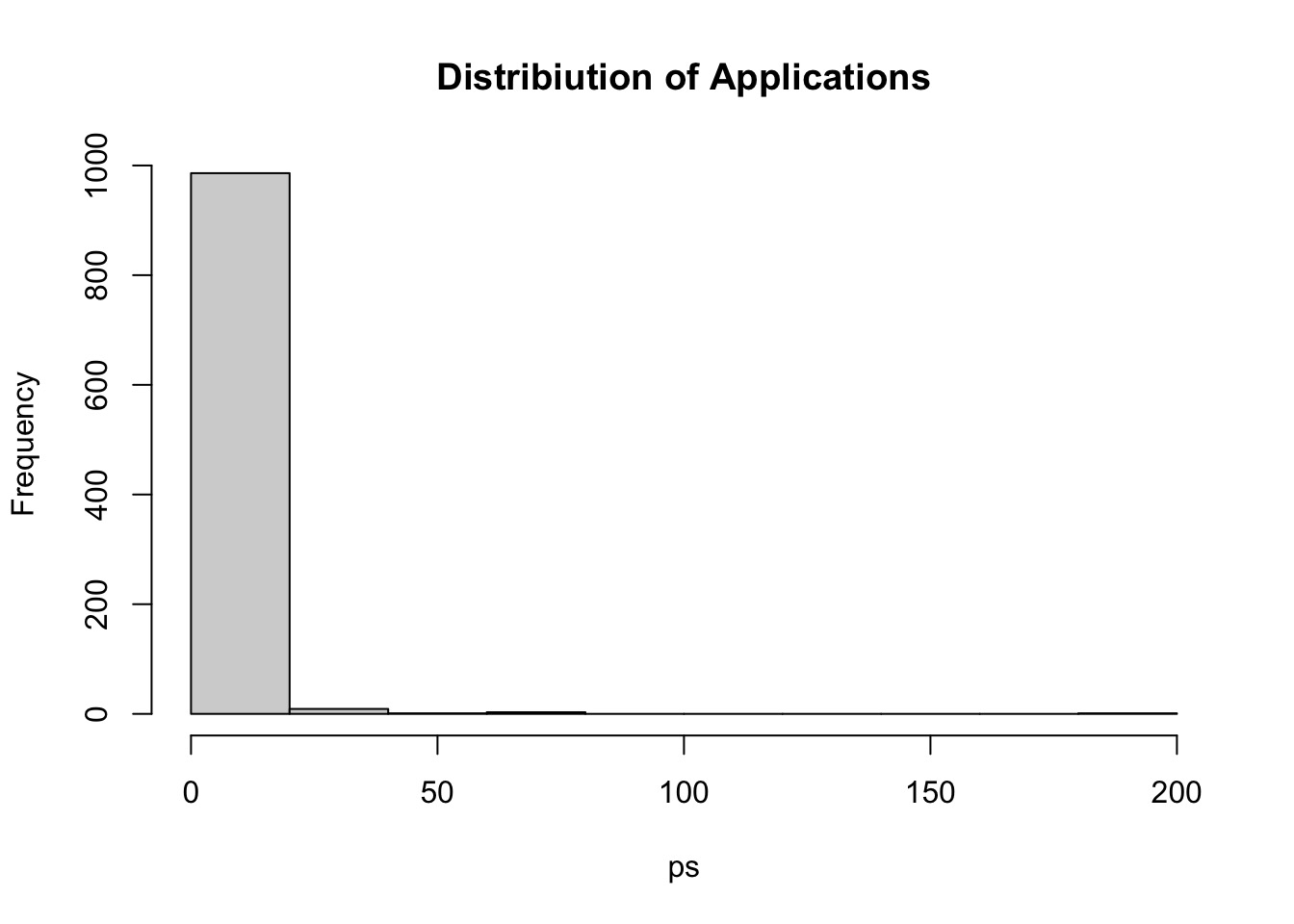
#Let's simulate some priors!prior_sims_apply <-extract.prior(fit_apply_add)# What would 1 dept look like for one gender?ps <-exp(prior_sims_apply$a[,1] + prior_sims_apply$b[,1]) hist(ps, main ="Distribiution of Applications")