Bayesian Approaches to Mixed (aka Hierarchical, aka Multilevel) Models
![]()
Mixed Models
- We have used these to tease out variation in parameters due to “blocks”
- Many kinds of “blocks”
- Variation can affect slopes and intercepts
- Variation can come from continuous “blocks” - Gaussian Process Models
- But what do we gain?
Gains from a Mixed Model Approach
- Shrinkage of Estimators
- Accurate post-hoc comparisons
- Better ability to make focused predictions
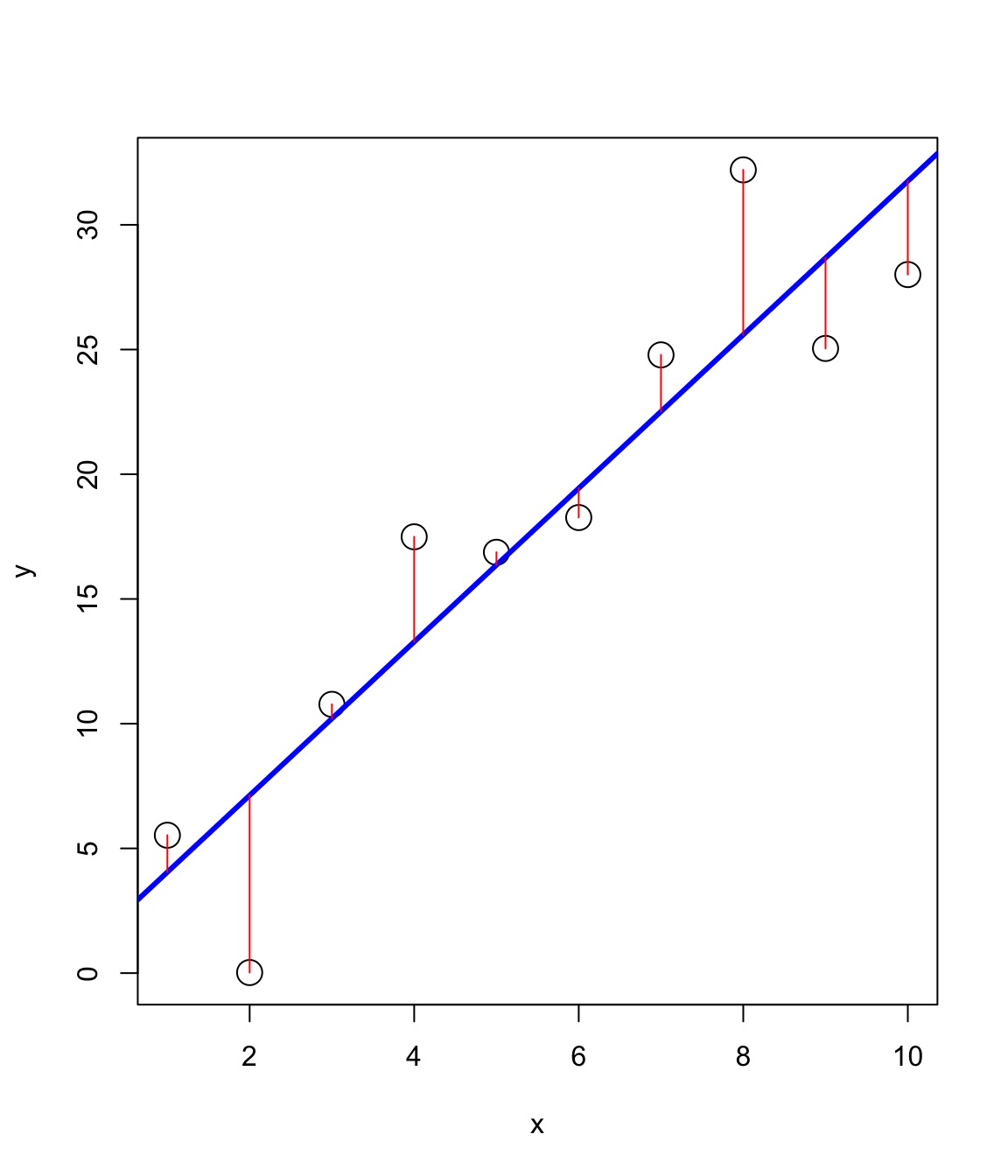
The Incredible Shrinking Frogs
![]()
The Reed Frog Data
density pred size surv propsurv
1 10 no big 9 0.9
2 10 no big 10 1.0
3 10 no big 7 0.7
4 10 no big 10 1.0
5 10 no small 9 0.9
6 10 no small 9 0.9
Tank as a block
- 48 tanks
- Each tank has different number of frogs
- Each frog is a “replicate”
- Each tank is a “block”
Three ways of looking at survivorship
1. Every tank has the same survivorship (complete pooling)
2. Every tank has its own unique survivorship (no pooling)
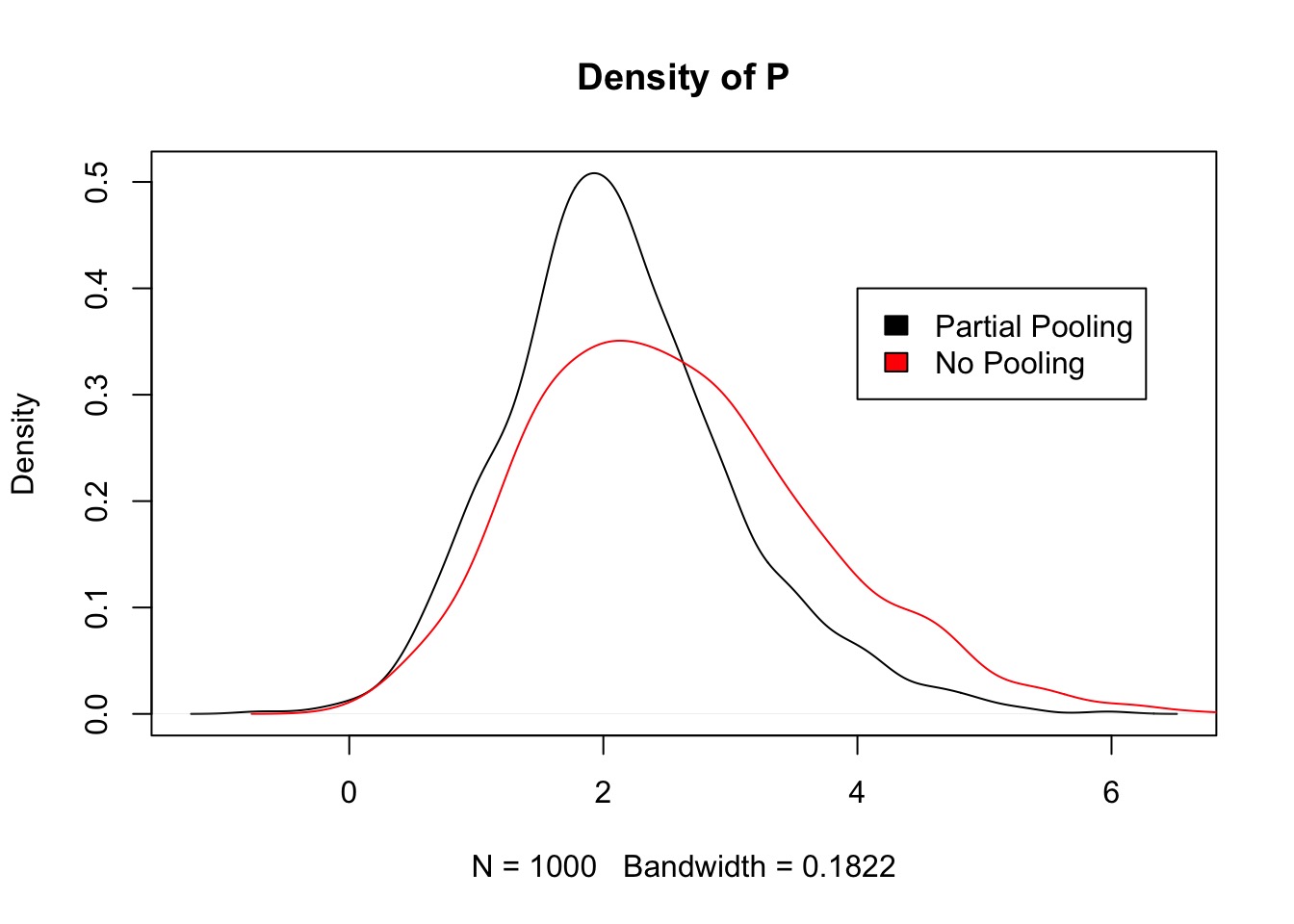
3. Every tank is similar to others, but with some variation in survivorship (partial pooling)
Complete Pooling
Estimates mean probability across all tanks
No Pooling
Each tank is independent
Partial Pooling and Hyperparameters
p[tank] ~ dnorm(0,10)
P[tank] can be anything, and our prior for p[tank] shows a distribution of possible values
But now…
p[tank] ~ dnorm(p_hat, sigma_tank)
P[tank] is drawn from a distribution, and p_hat and sigma_tank are hyperparameters, each with their own prior
This can go on forever…
![]()
Partial Pooling
\[p_j \sim dnorm(\widehat{p} , \sigma_{tank})\]
The Mathy Version
Likelihood
\(Survivors_j \sim dbinom(density_j , prob_j)\)
Data Generating Process
\(logit(prob_j) = p_j\)
\(p_j \sim dnorm(\widehat{p} , \sigma_{tank})\)
Priors
\(\widehat{p} \sim dnorm(0,10)\)
\(\sigma_{tank} \sim dcauchy(0,2)\)
Why Partial Pooling?
- Share information across blocks
- estimate of one block informs the other
- super helpful with unbalanced designs
- Enables Best Least Unbiased Predictor (BLUP) of observations
- Reduces number of effective parameters
- Improved estimation of true underlying parameter
- Observed values have additional error, reduces accuracy