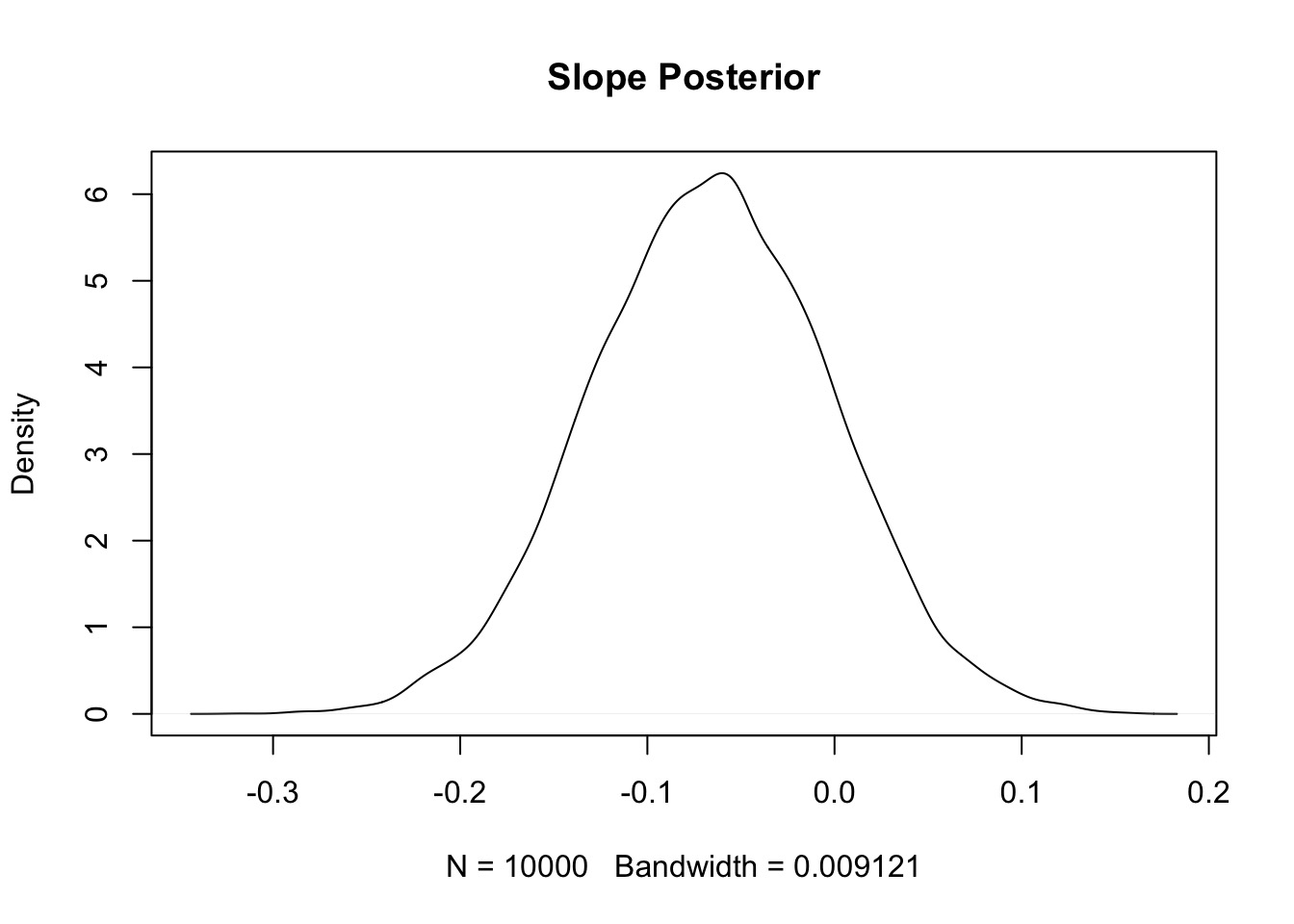
Markov Chain Monte Carlo

Our Story Thus Far…
- We have been using Maximum A Posteriori Approximations
- Assumes Gaussian posterior (approximately quadratic)
- Great for simple models
King Markov and His Islands

King Markov and His Islands

How to move around Islands
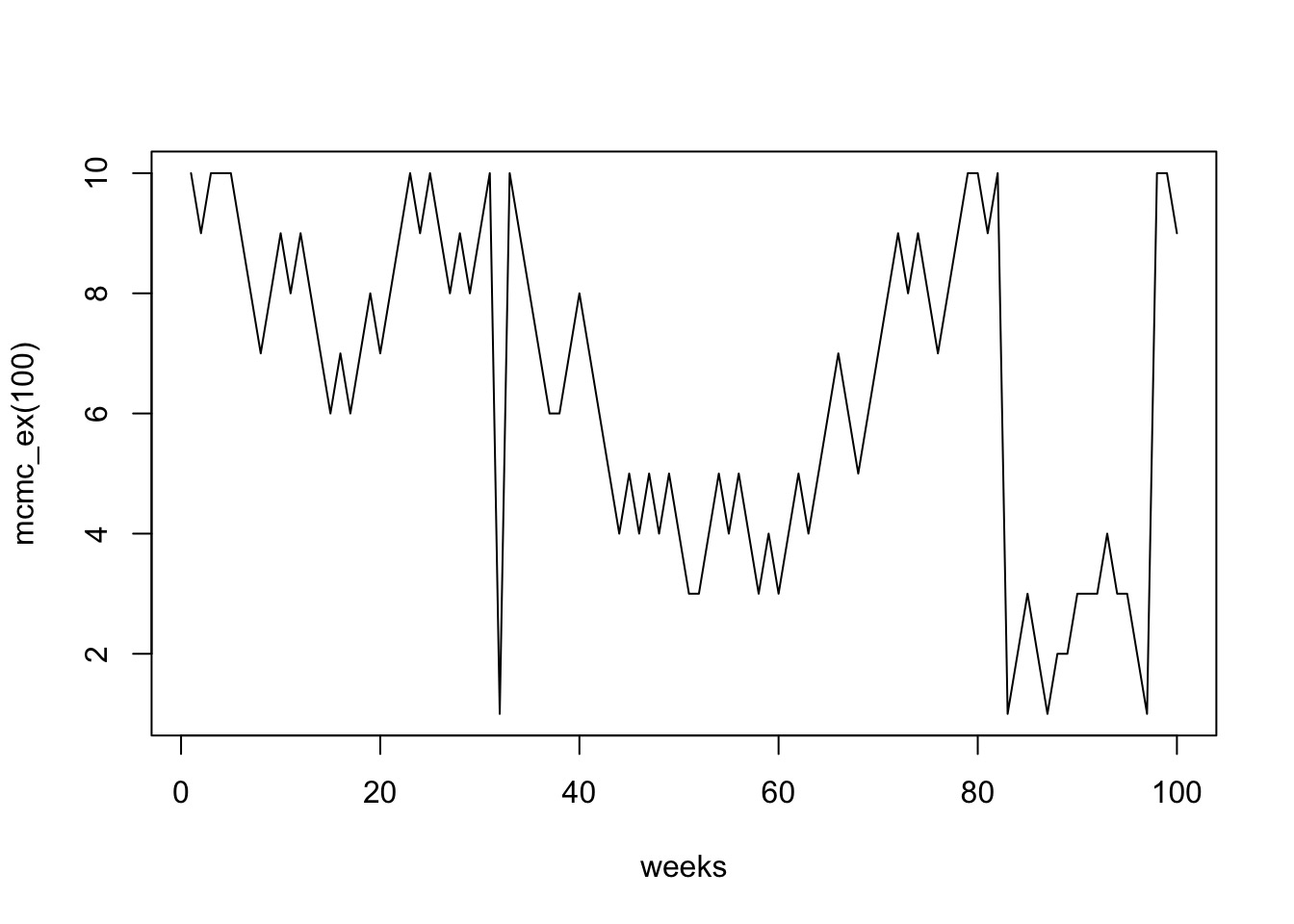
Metropolis MCMC in Action: 10 Weeks
Population = Island Number 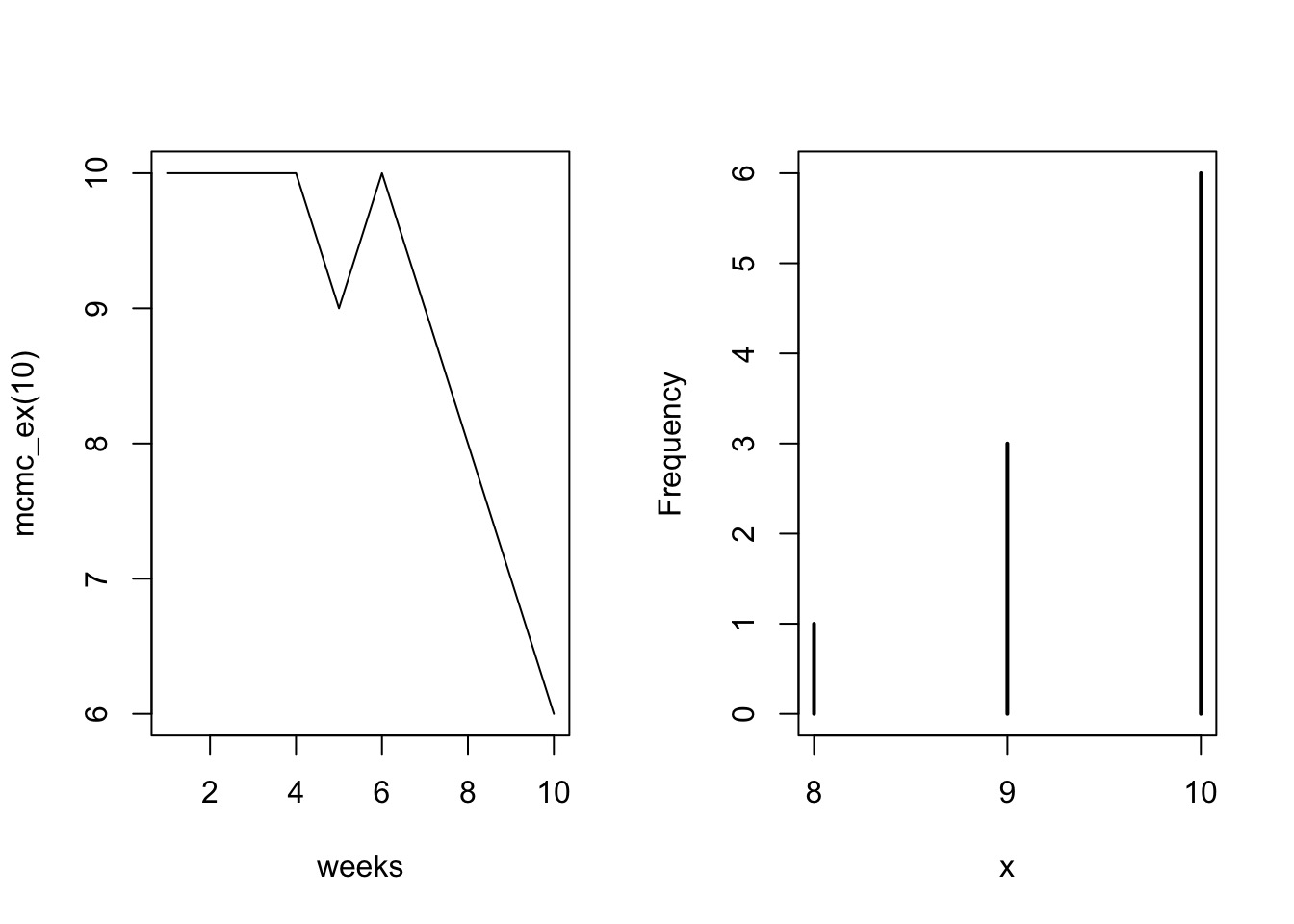
Metropolis MCMC in Action: 50 Weeks
Population = Island Number 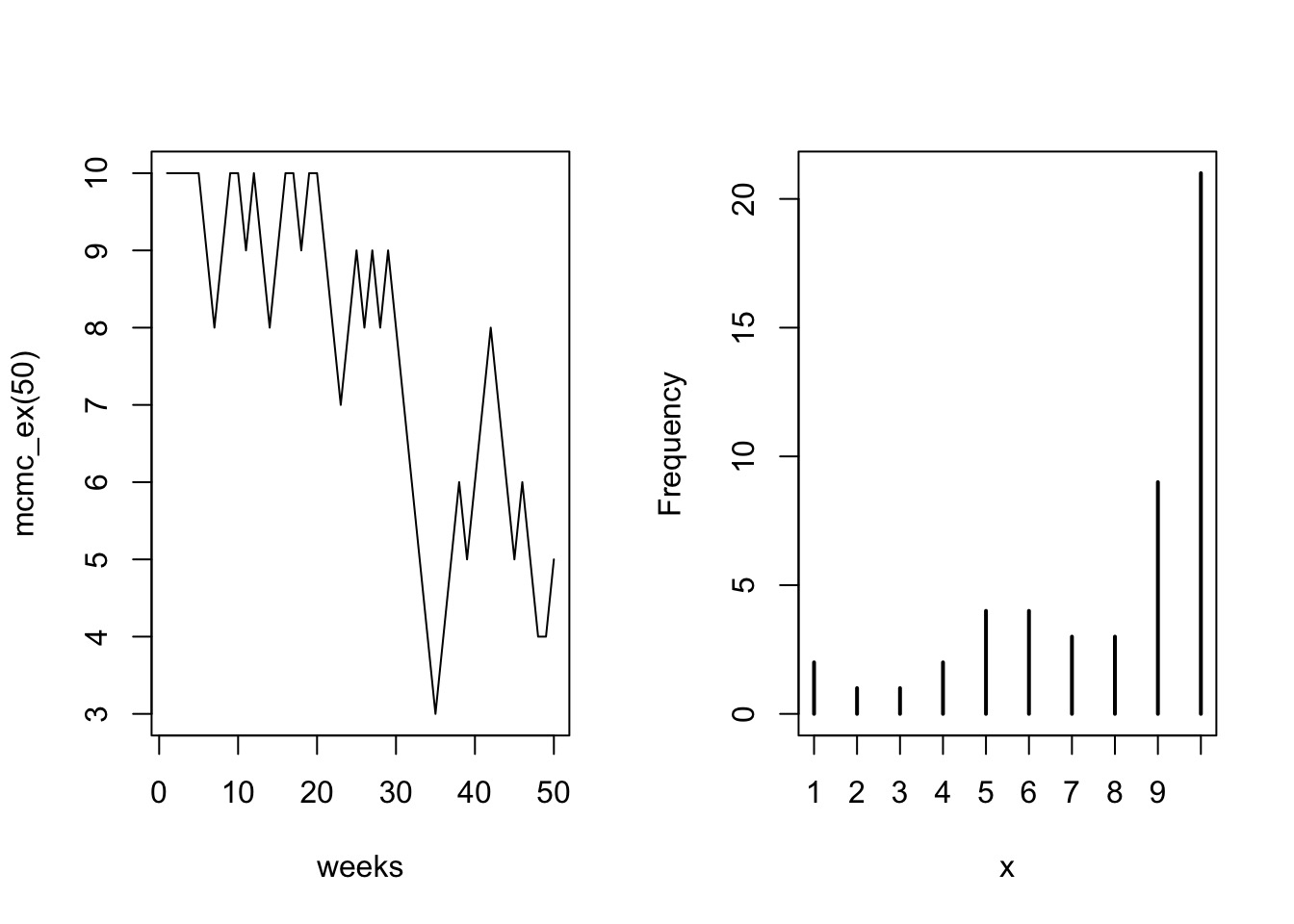
Metropolis MCMC in Action: 1000 Weeks
Population = Island Number 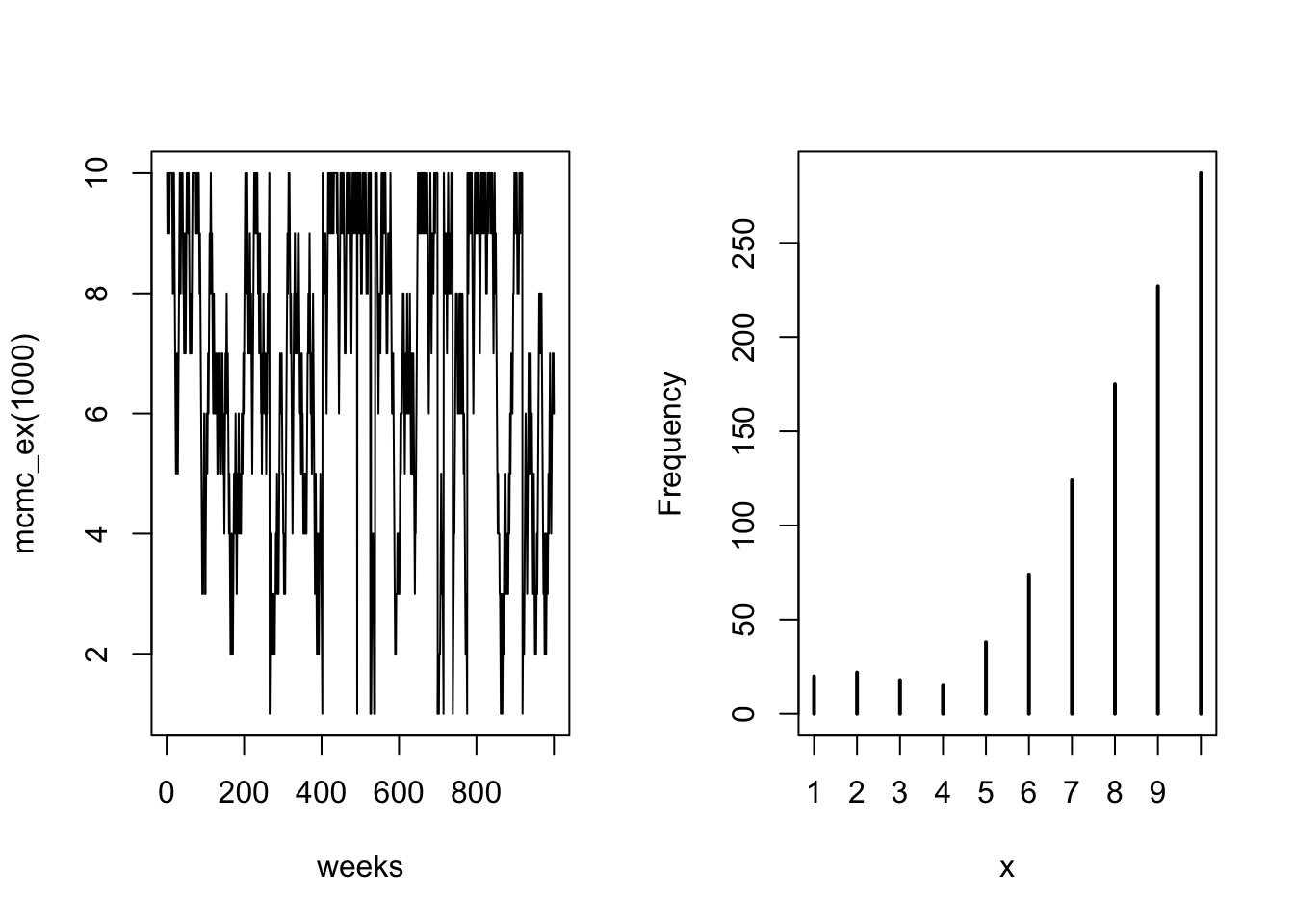
Metropolis MCMC For Models
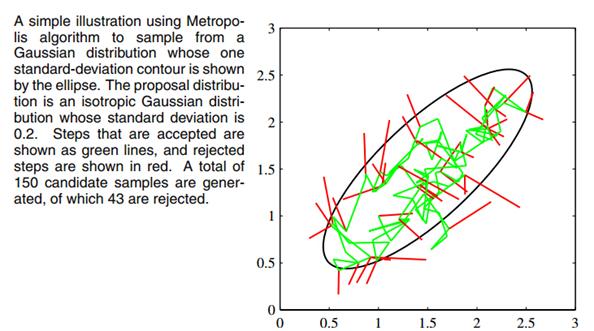
- Each island is a set of parameter choices
- Each “population” is a posterior density
- The path is a ‘chain’
- Note the autocorrelation - we “thin” chains
- Only use every ith sample so that there is no autocorrelation
MCMC In Practice for Models
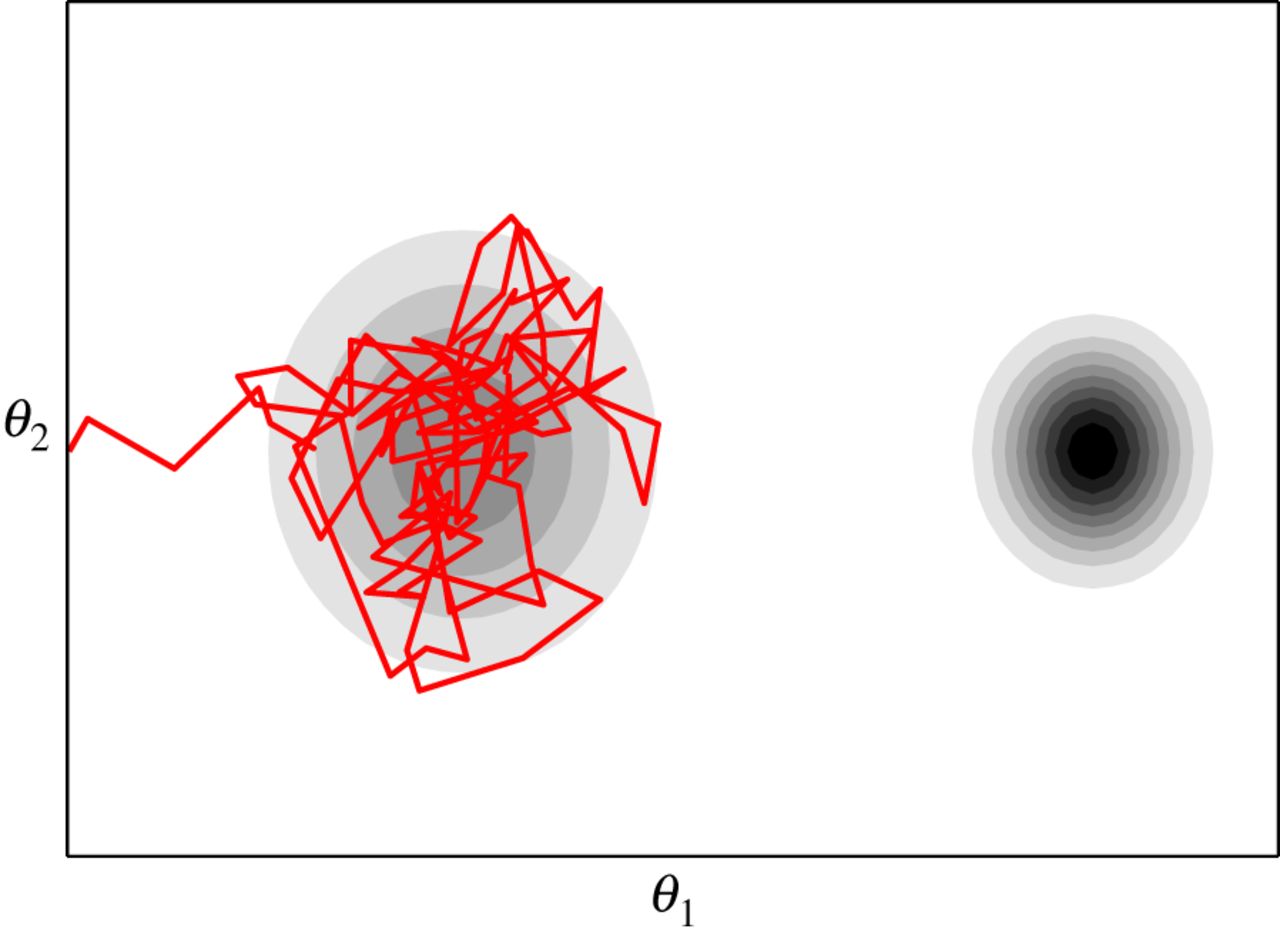
MCMC is not a Panacea

MCMC is not a Panacea
MCMC Algorithms
- Metropolis MCMC inefficient
- Many algorithms to come up with clever proposed moves to speed up
- Gibbs sampling used for BUGS, JAGS, etc.
- Still has same problems as Metropilis
- Or… Abandon search and use more deterministic sampling
- Hamiltonian MCMC

King Hamilton and His BatBoat

King Hamilton and His BatBoat
- Boat passes by all of the island, back and forth
- Boat slows down to see people in porportion to how many folk
- We sample position through time, more positions in areas where boat is slow
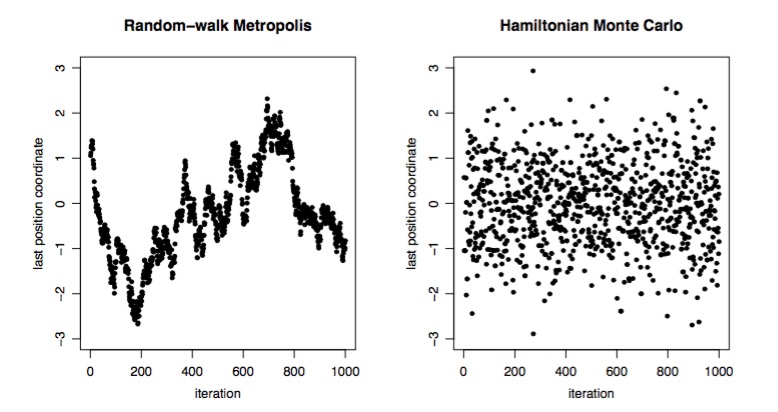
Metropolis versus Hamiltonian
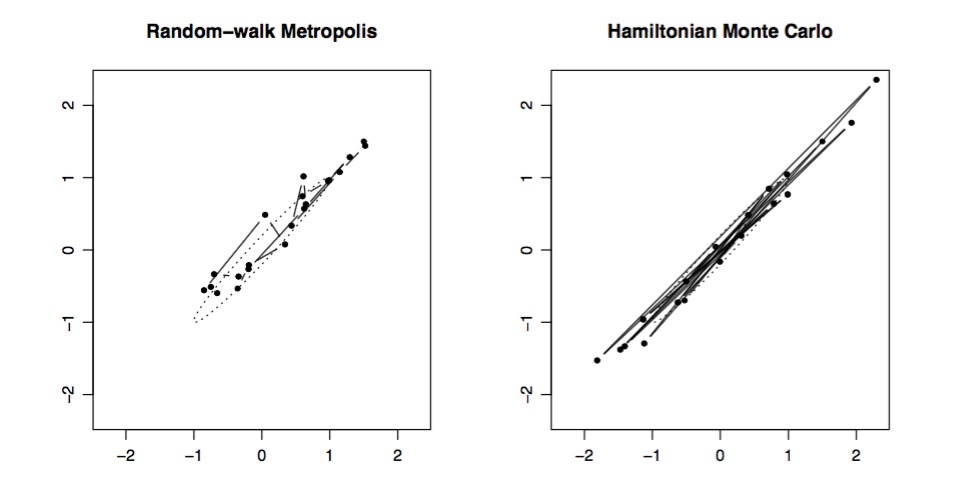
Metropolis versus Hamiltonian
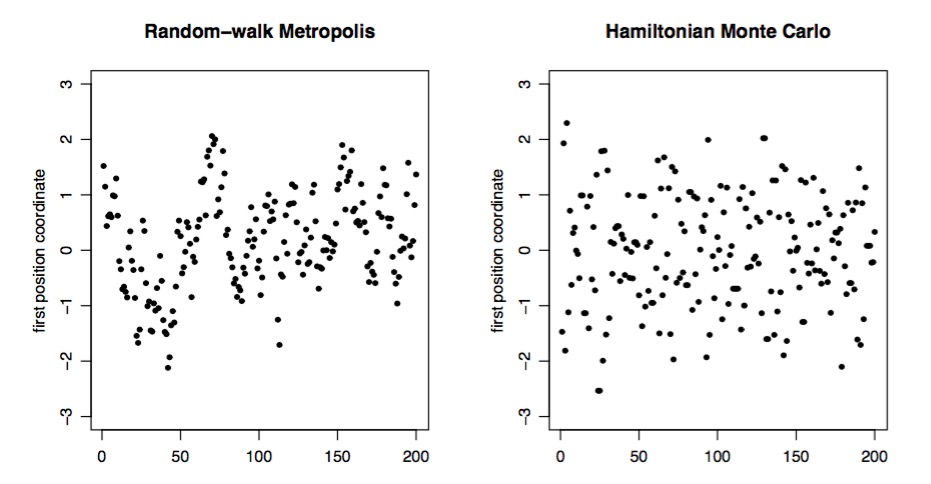
Metropolis versus Hamiltonian
Implementing HMCMC via Stan

- We use the
map2stanfunction to call STAN- Compiles a model, so it can take a while
- Compiles a model, so it can take a while
- Can specify number of chains and other parameters
- And now our samples are already part of our model!
- Careful, models can get large (in size) depending on number of parameters and samples
Sidenote: the Cauchy Distribution
- Pronounced Ko-she
- A ratio of two normal distributions
- Large thick tail
- Extreme values regularly sampled
- Uses half-cauchy, so, only positive

Inspect your Chains for convergence!
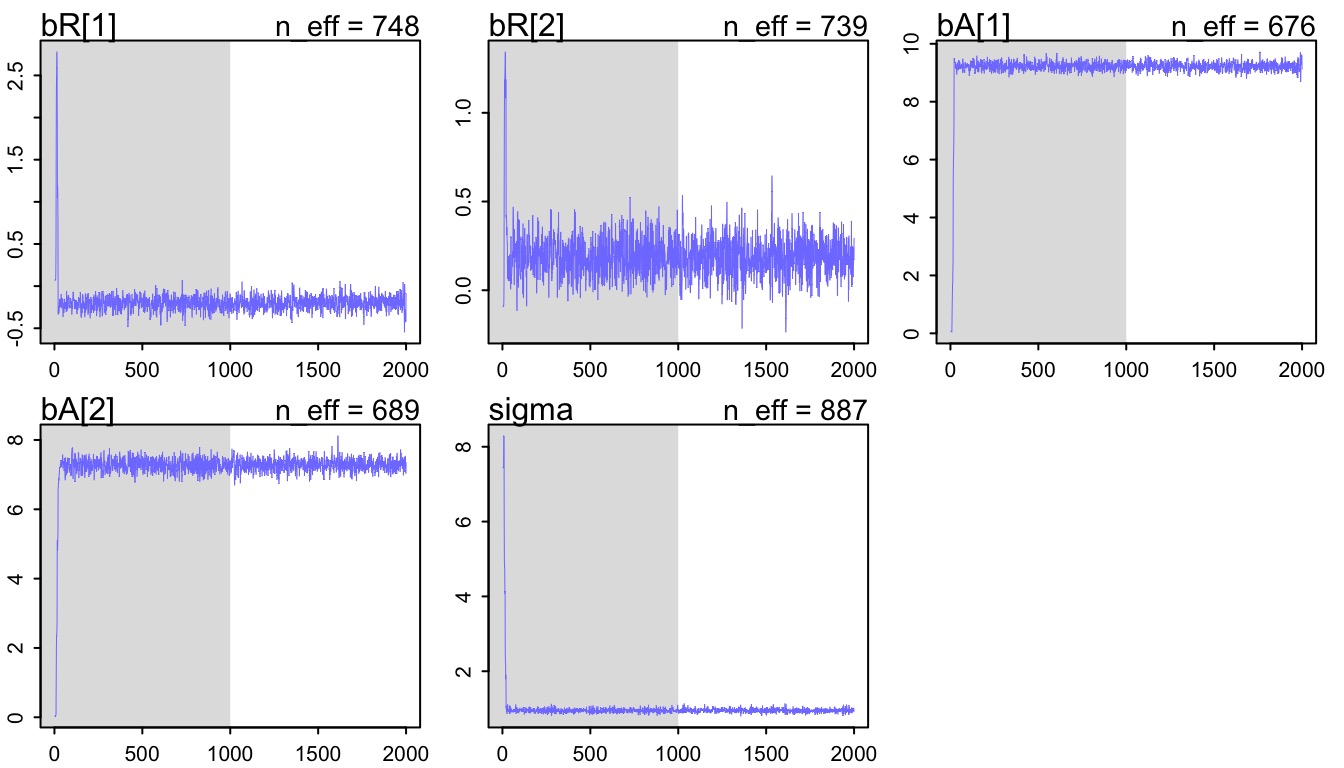
- Note, grey area is “warmup”
- Warmup is the BatBoat motoring around, tuning up
- Not used for posterior
- Warmup is the BatBoat motoring around, tuning up
Multiple Chains
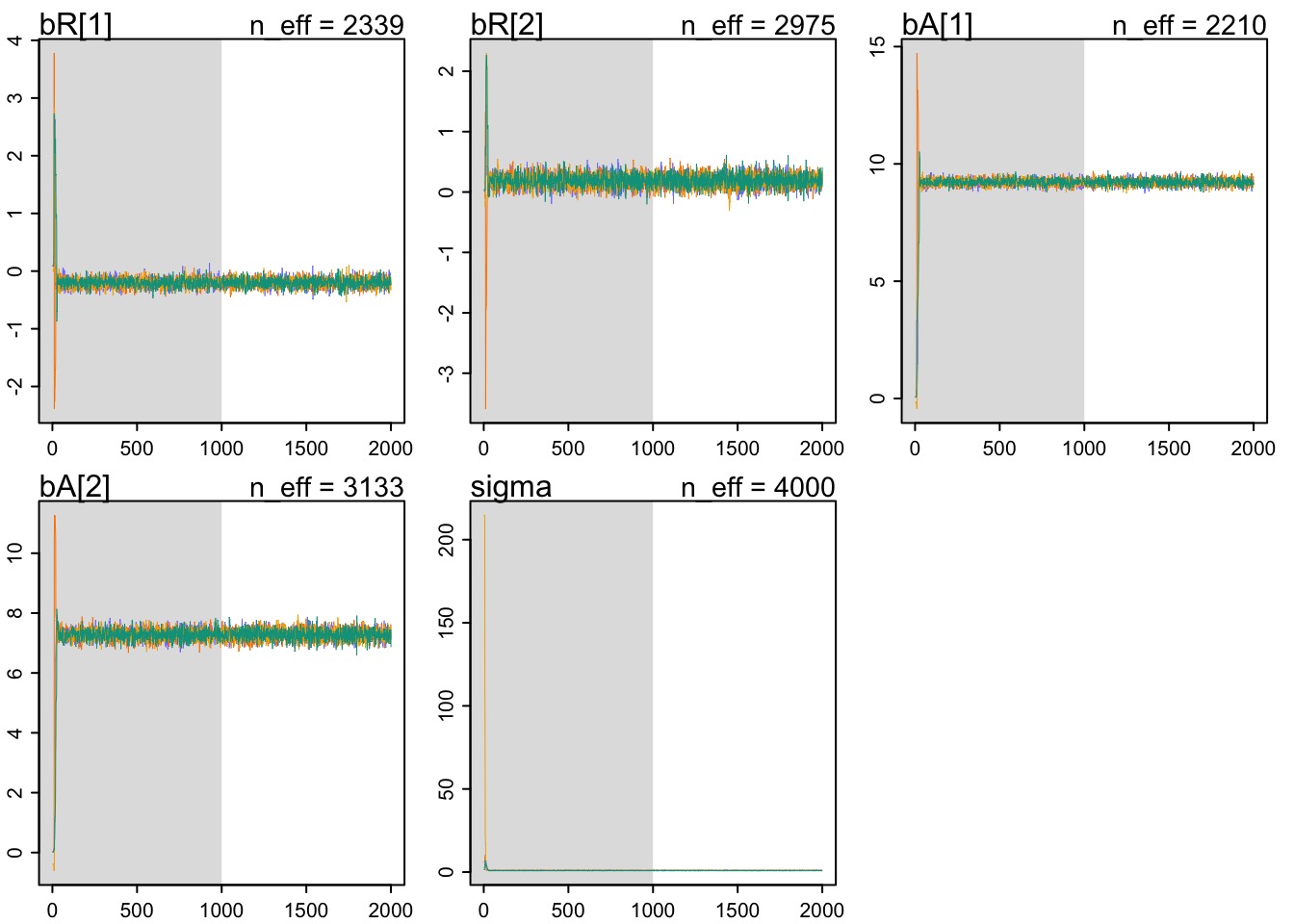
What do bad chains look like?
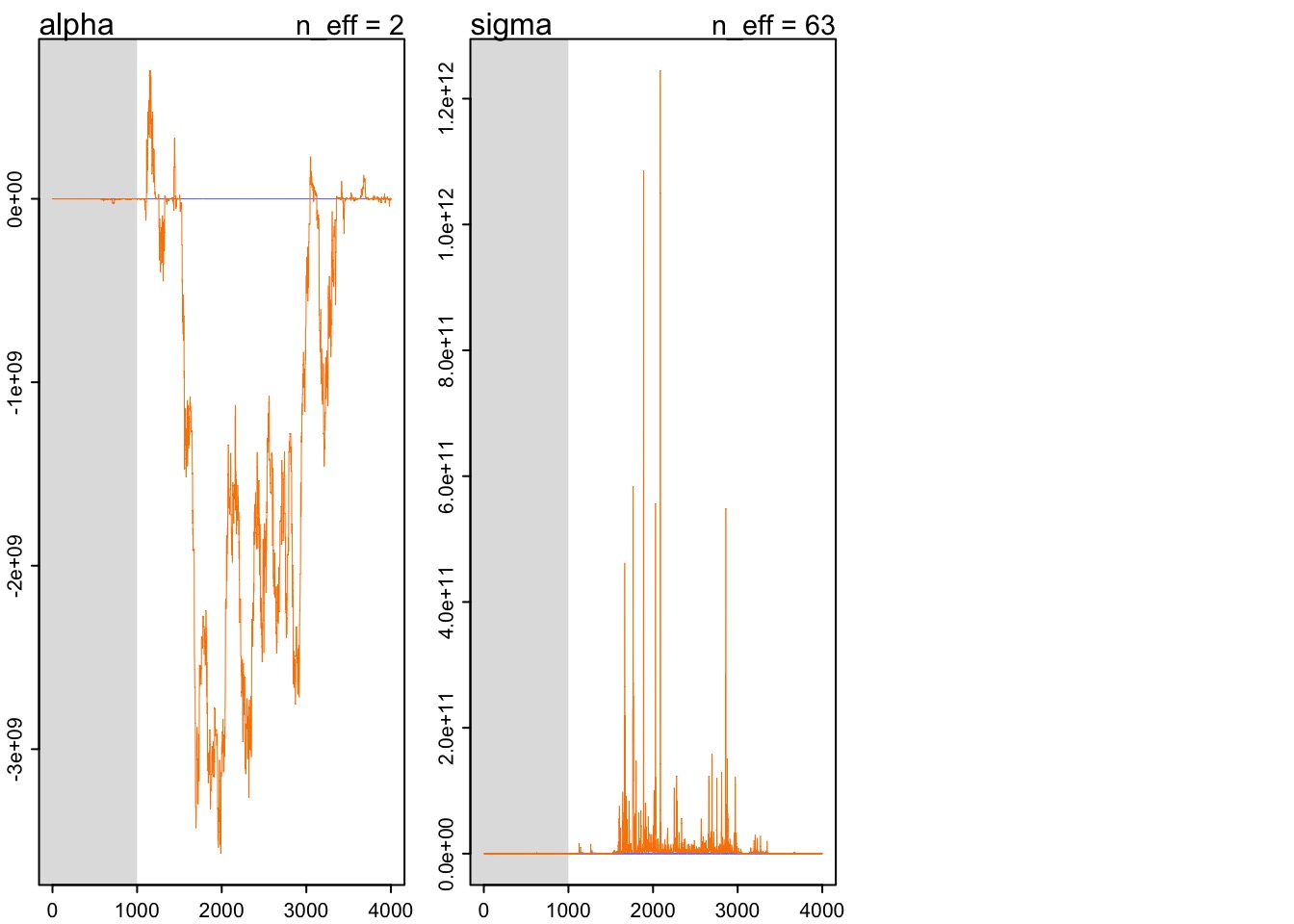
Lack of Convergence
- Might be that model has not found good values
- More likely bad model
- Too many parameters
- Redundant parameters
- Poor fit to data

- Too many parameters