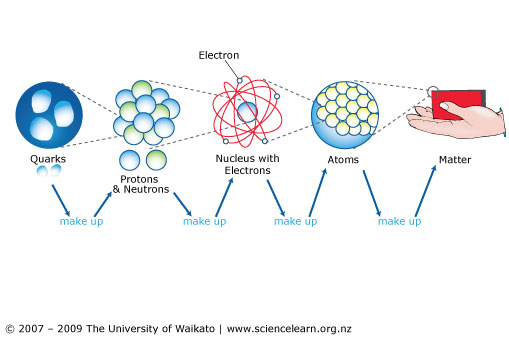
Information Theory and a Multimodel World

How complex a model do you need to be useful?
Some models are simple but good enough

More Complex Models are Not Always Better or Right
Underfitting
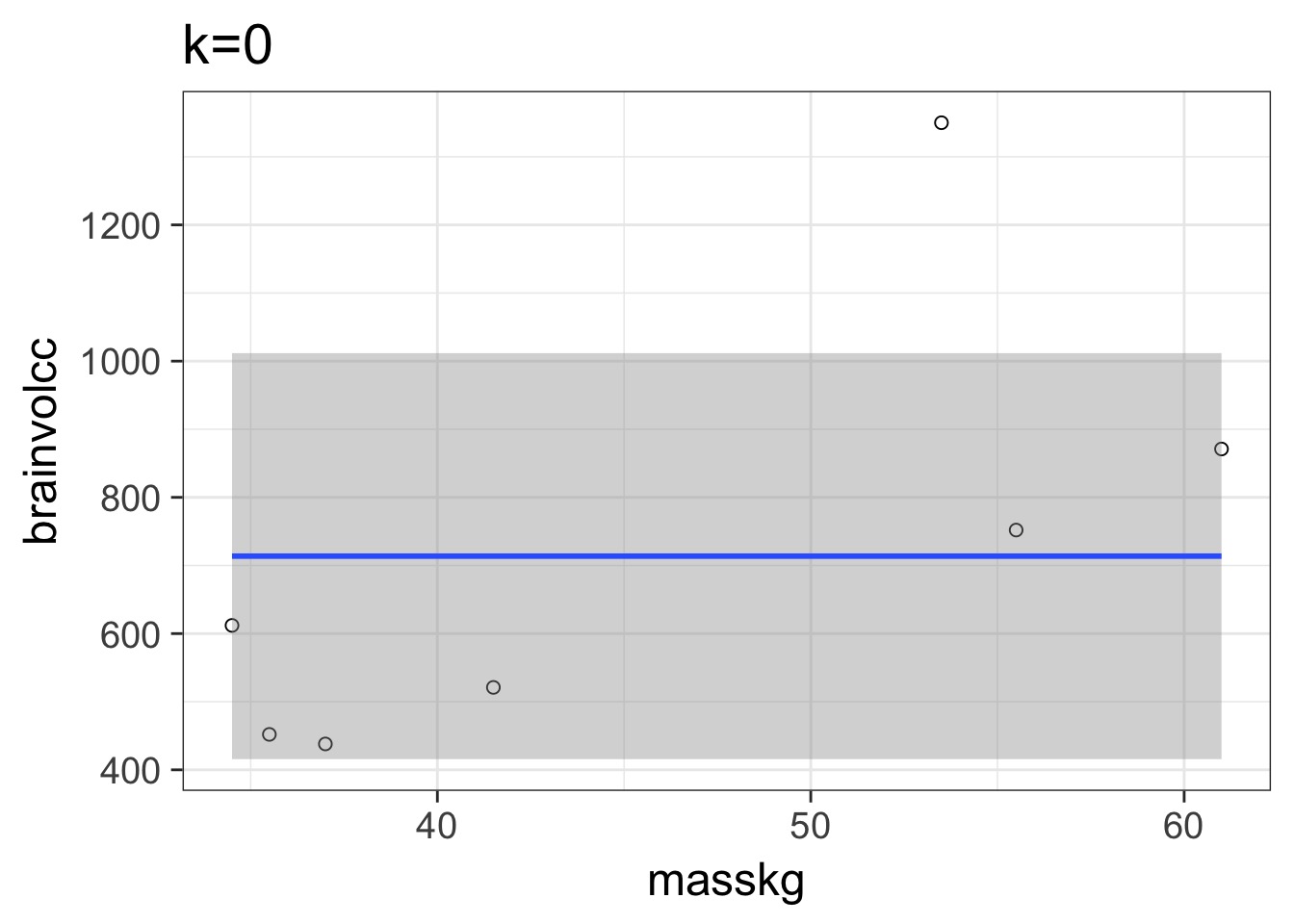
We have explained nothing!
Overfitting
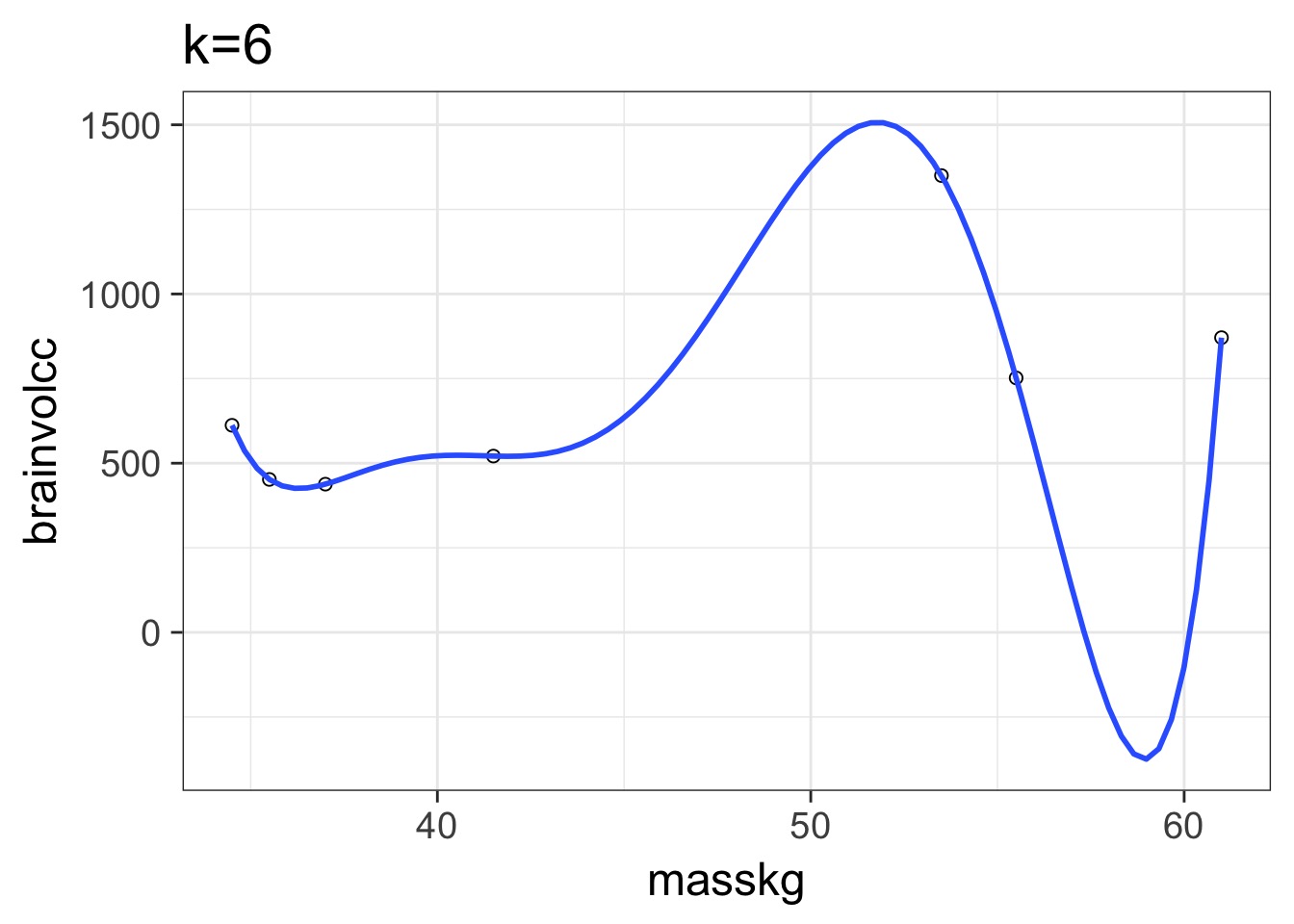
We have perfectly explained this sample
What is the right fit?
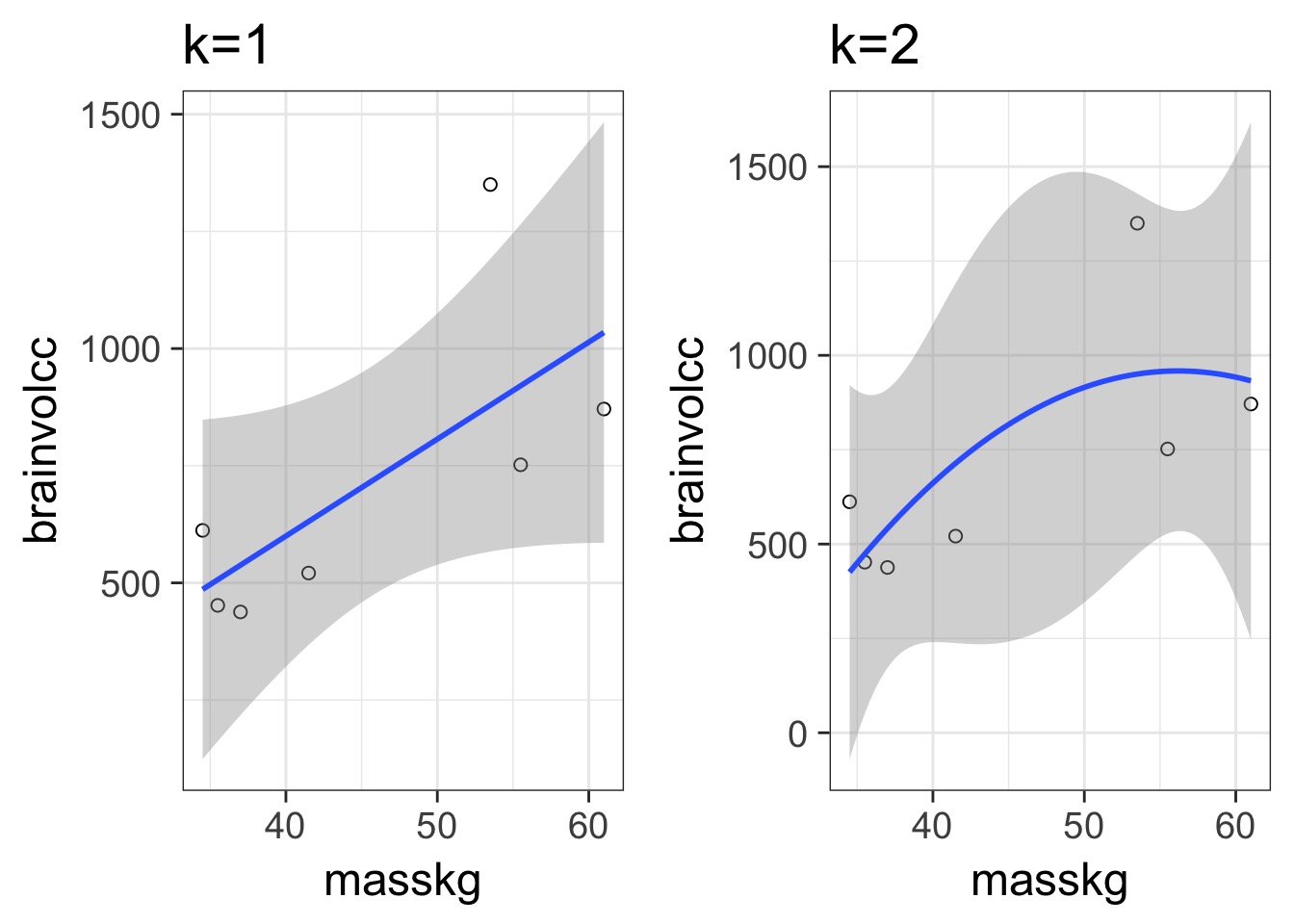
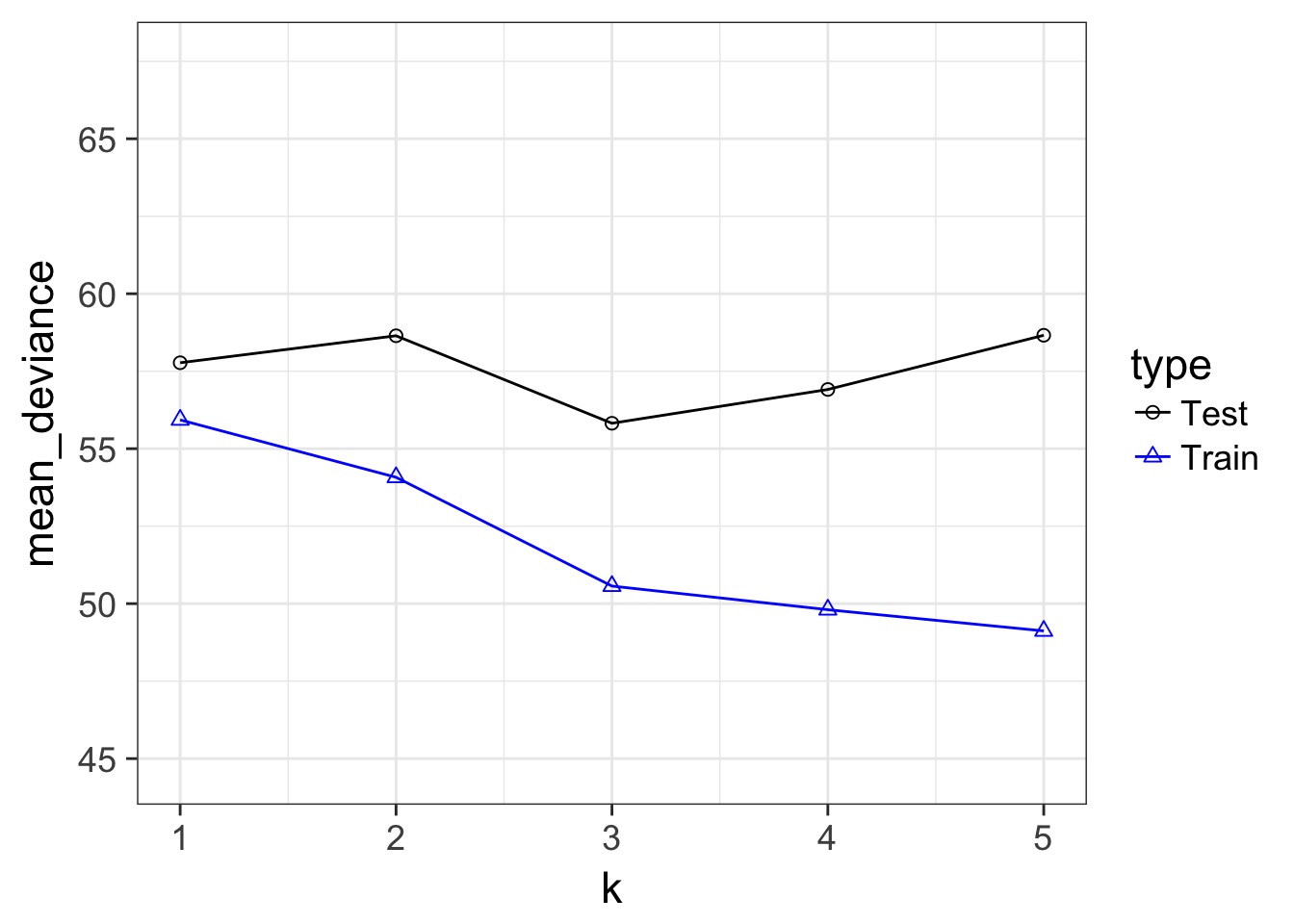
In and Out of Sample Deviance
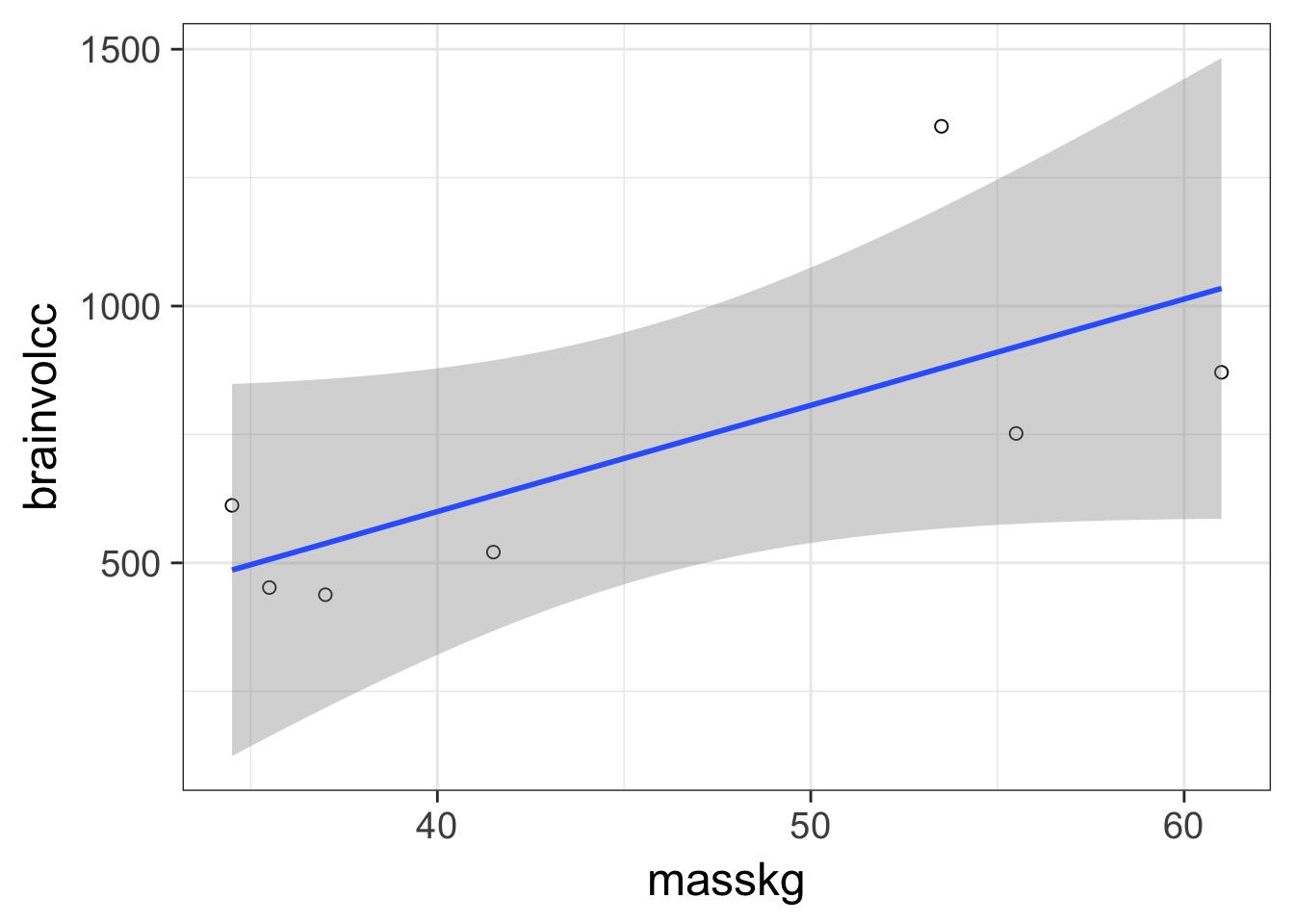
Deviance = -2 * log(dnorm(\(y_i | \mu_i\)))
The deviance of this linear regression is 3.176628510^{5}
In and Out of Sample Deviance
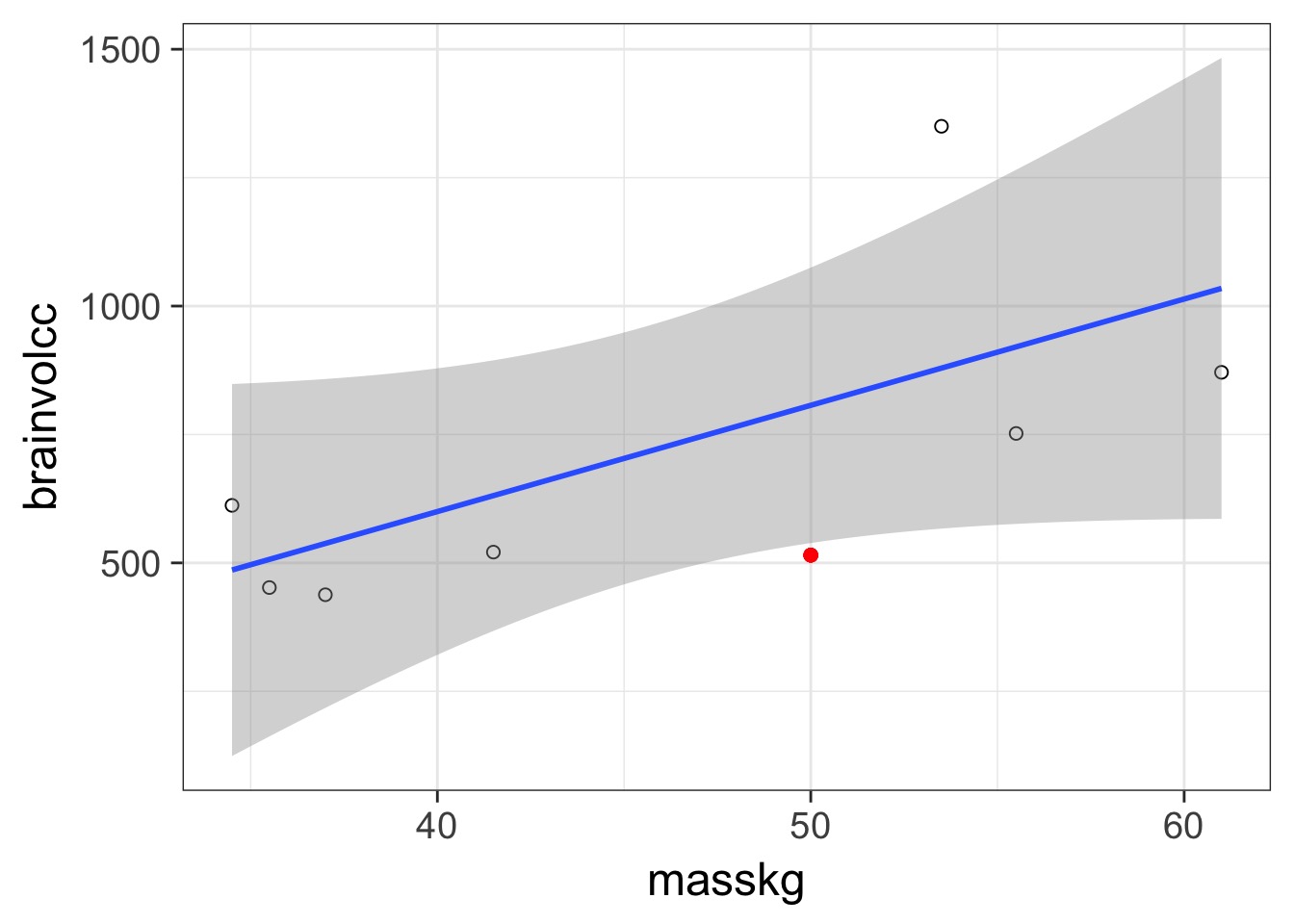
Prediction: 806.8141456, Observe: 515
Deviance: 8.526583810^{4}
In and Out of Sample Deviance
Regularlization
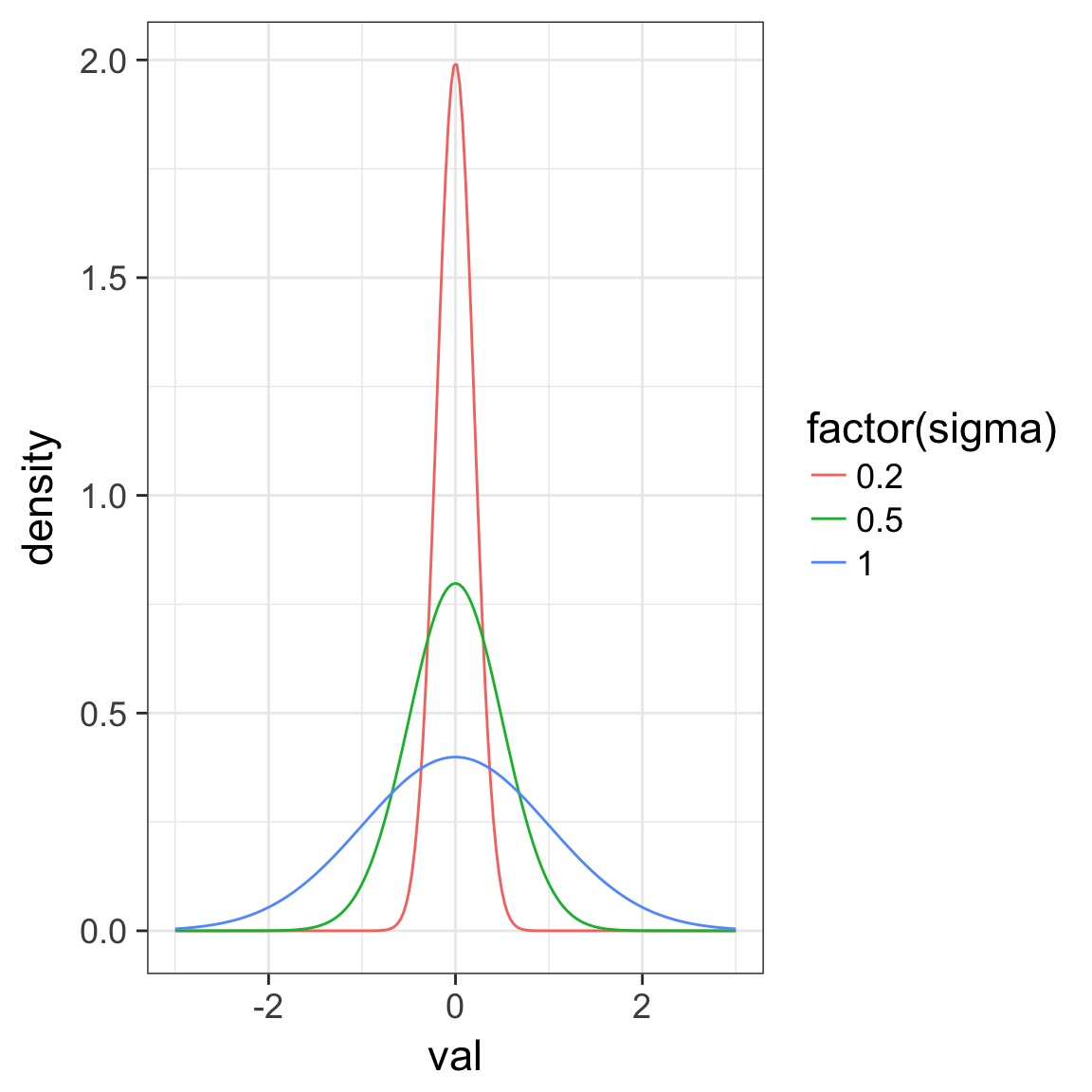
- Regularization means shrinking the prior towards 0
- Means data has to work harder to overcome prior
- Good way to shrink weak effects with little data, which are often spurious
- But, requires significant tuning
Regularization and Train-Test Deviance
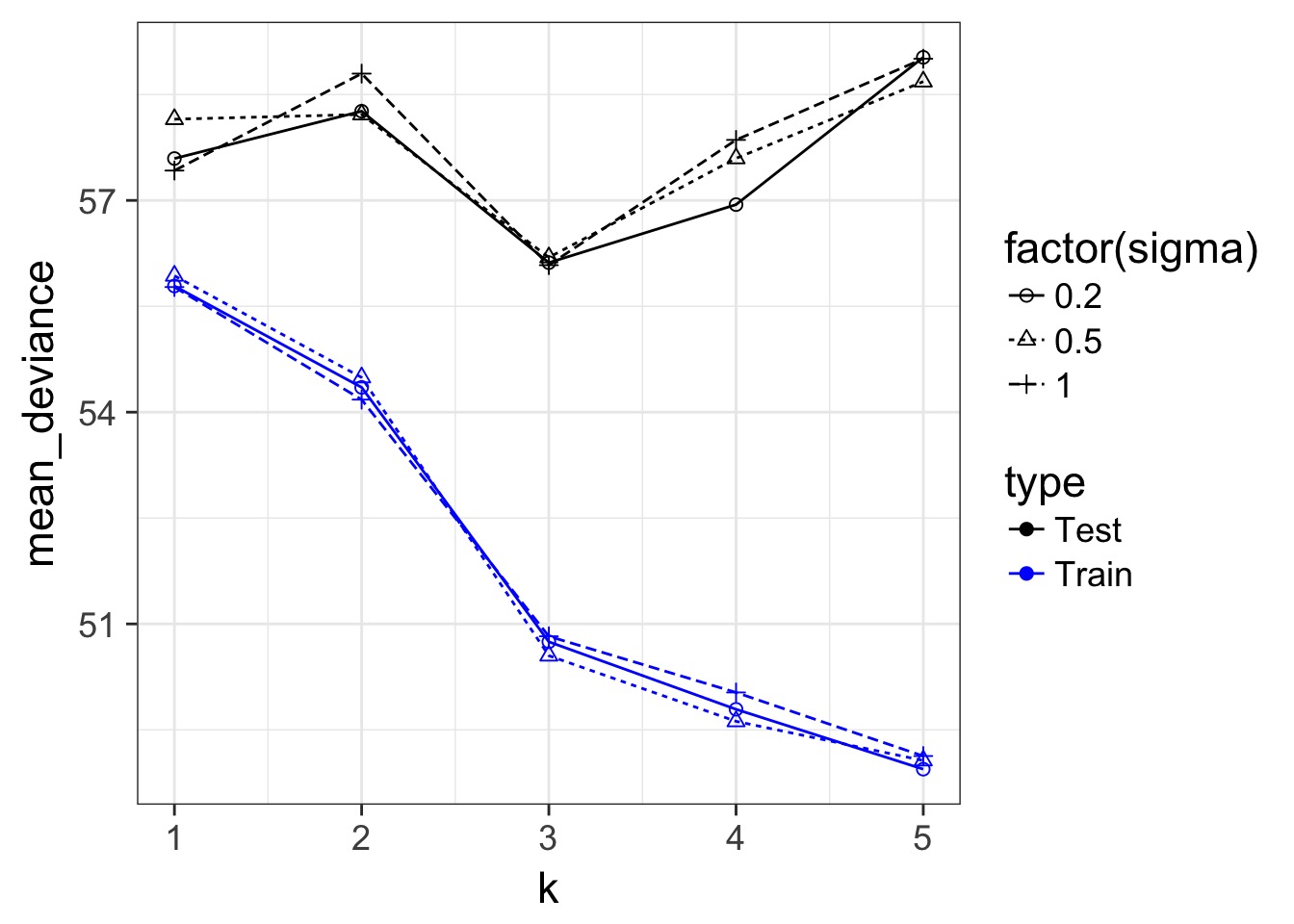
A Criteria Estimating Test Sample Deviance
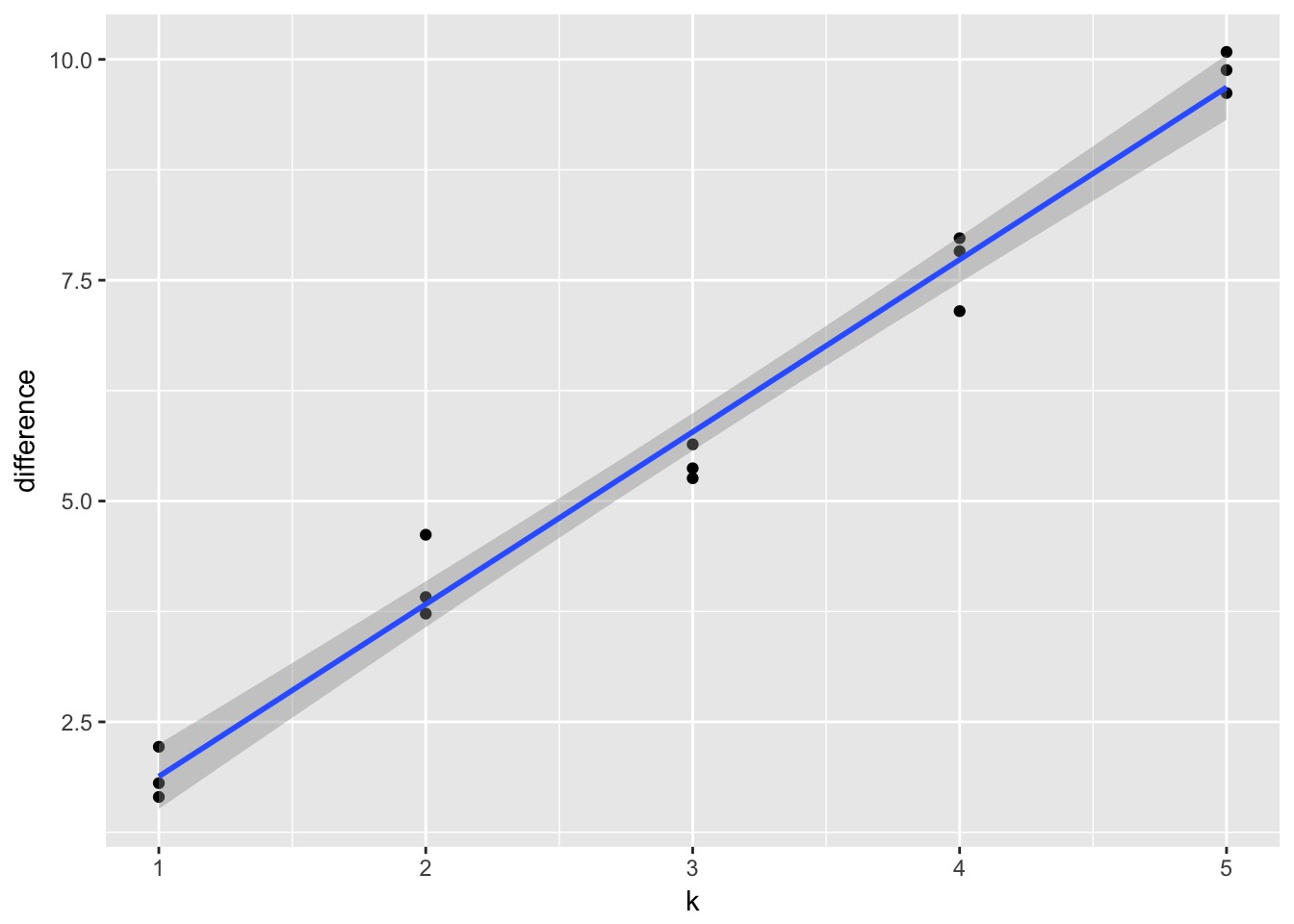 Slope here of 1.95
Slope here of 1.95
AIC

- So, \(E[D_{test}] = D_{train} + 2K\)
- This is Akaike’s Information Criteria (AIC)
\[AIC = Deviance + 2K\]
DIC

\[DIC = 2 \bar{D} - 2 p_D\]
Monkies and Milk

data(milk)
d <- milk[ complete.cases(milk) , ]
d$neocortex <- d$neocortex.perc / 100Comparing Models
plot(milk.models, cex=1.5)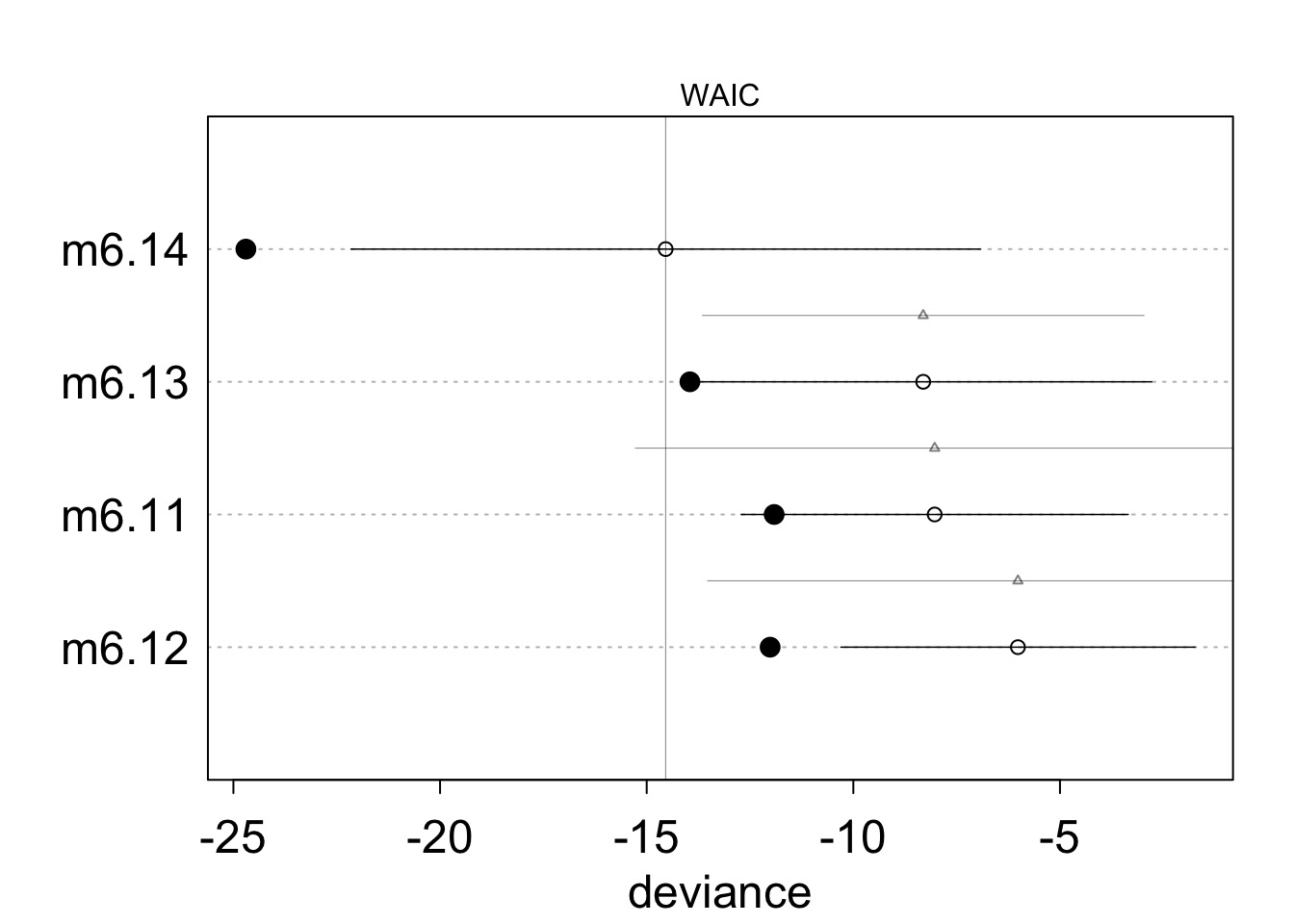


Coefficients
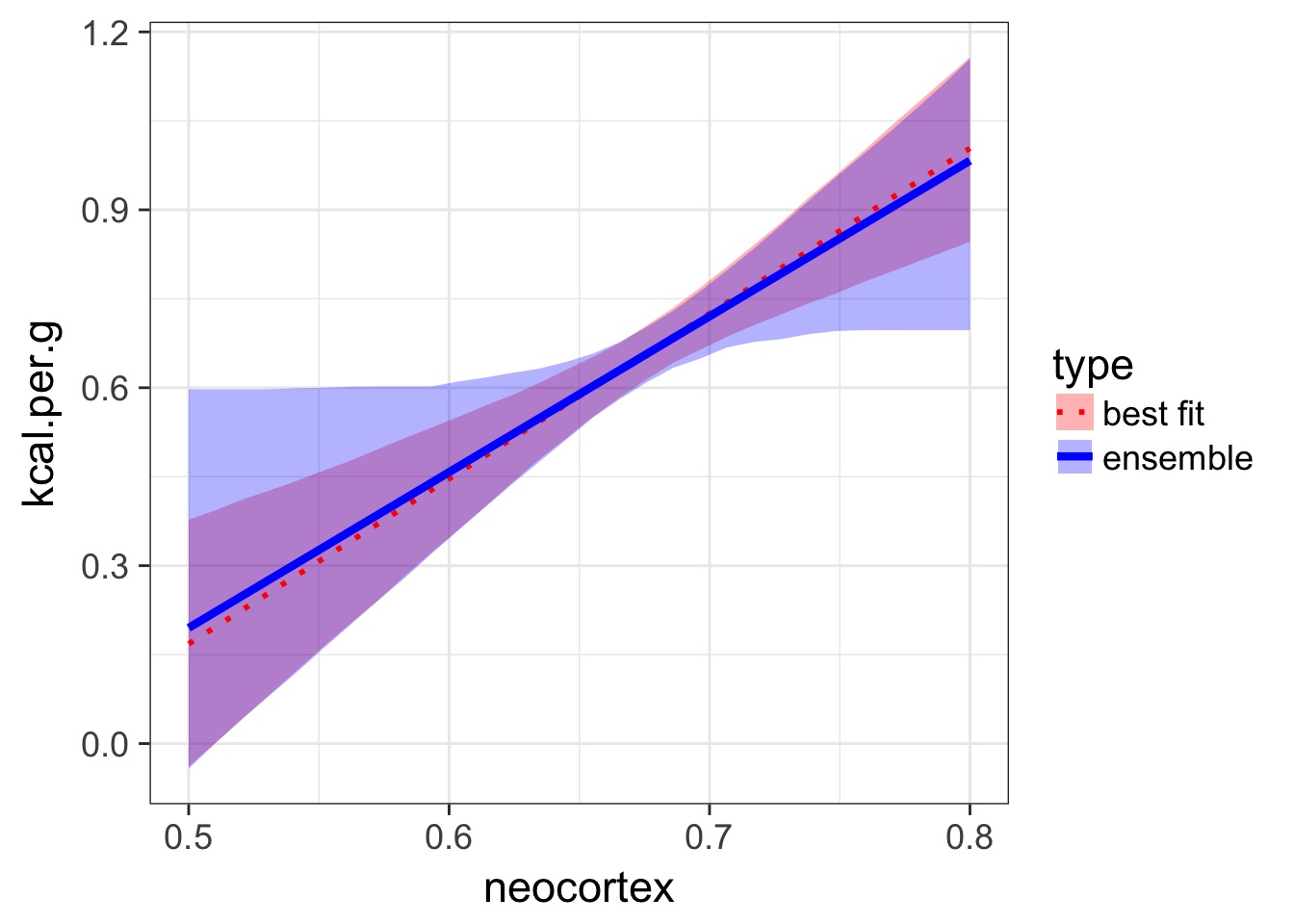
Remember, m6.14 has a 97% WAIC model weight
plot(ctab)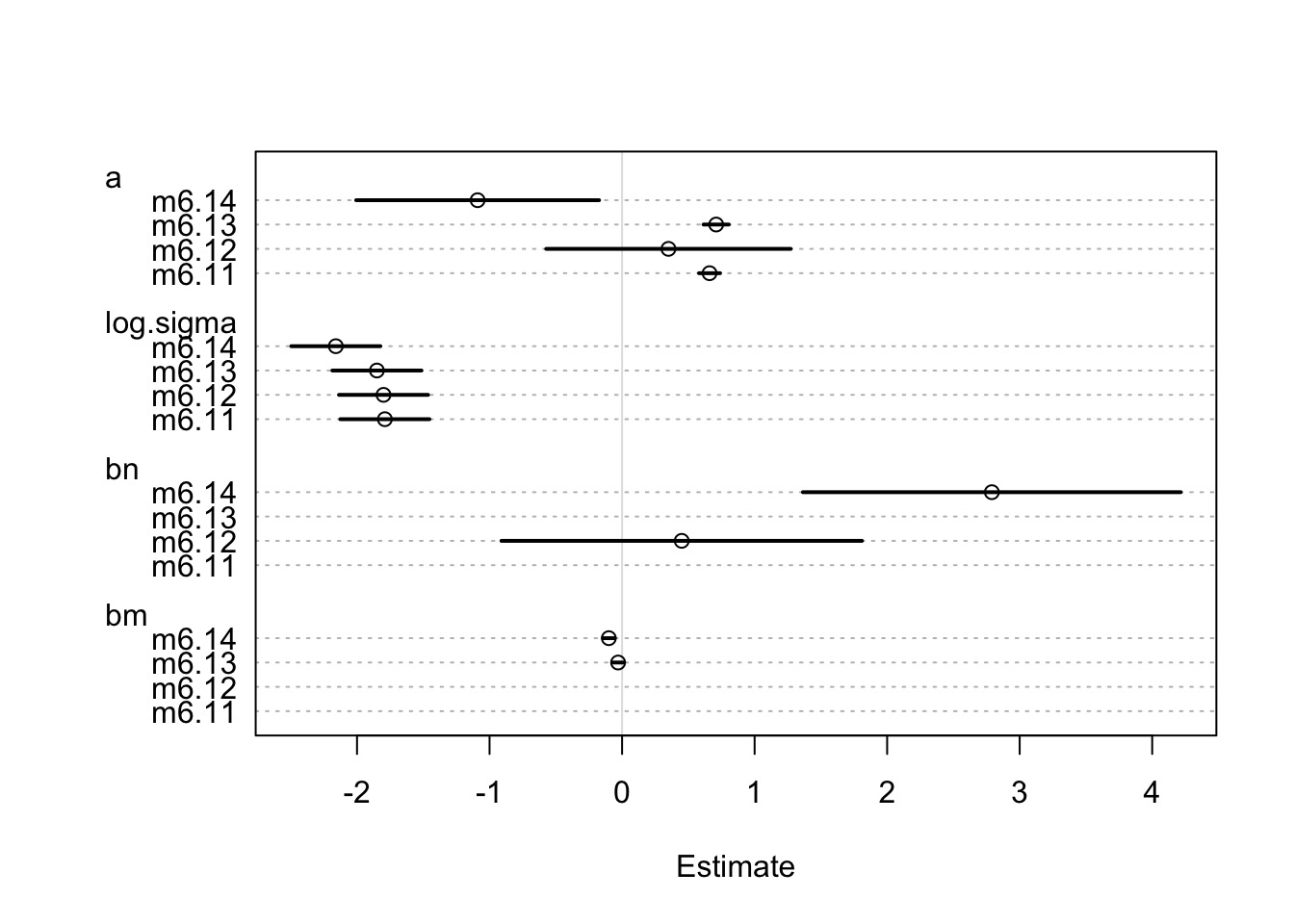
Making an Ensemble