Back to Bayes-ics
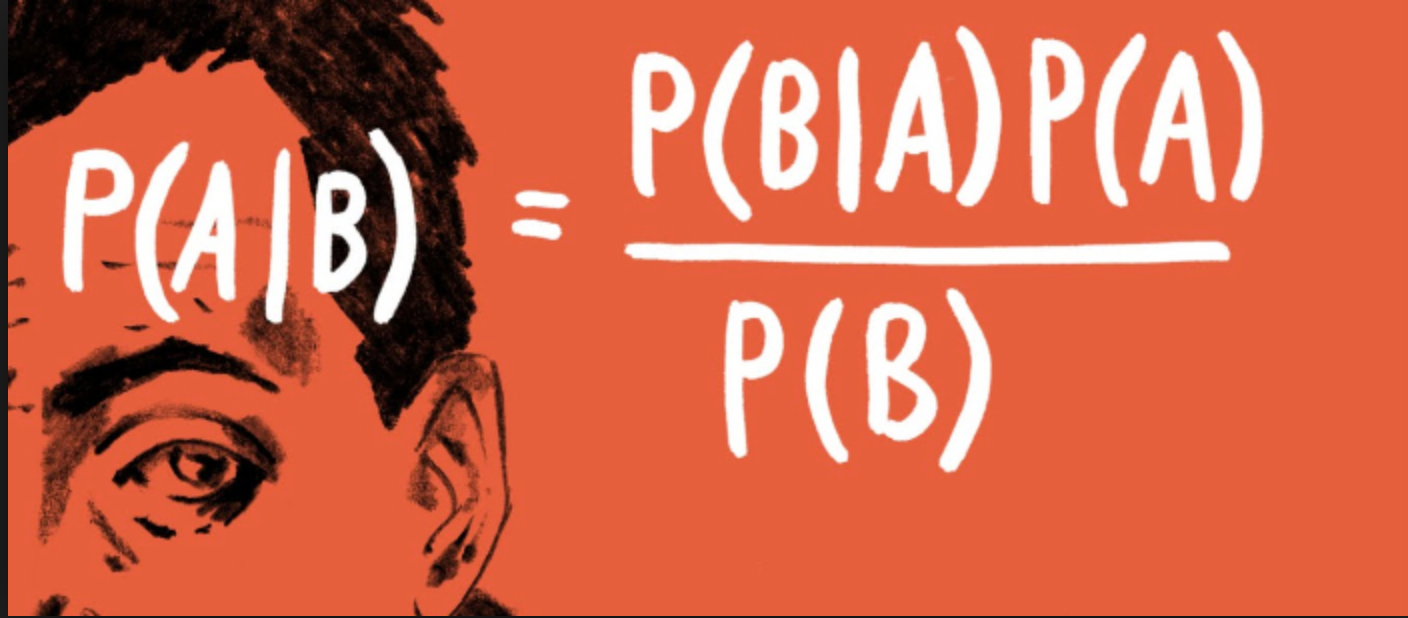
Bayesian Inference

Estimate probability of a parameter
State degree of believe in specific parameter values
Evaluate probability of hypothesis given the data
Incorporate prior knowledge
Why is this approach inherently Bayesian?

Bayes Theorem and Stones

- Each possibility = H
- Prior plausibility = P(H)
- P(Draw | H) = Likelihood
- Sum of all P(Draw | H) P(H) = Average Likelihood
- = P(Draw)
Bayes Theorem and Stones
\[p(H_i | Draw) = \frac{Likelihood\,* \,Prior}{Average\,\,Likelihood}\]
Bayes Theorem and Stones
\[p(H_i | Draw) = \frac{p(Draw | H_i) p(H_i)}{P(Draw)}\]
Bayes Theorem

\[p(Hypothesis | Data) = \frac{p(Data | Hypothesis) p(Hypothesis)}{P(Data)}\]
Bayesian Updating

Now let’s do that over again! And again!
Watch the Updating in Realtime!
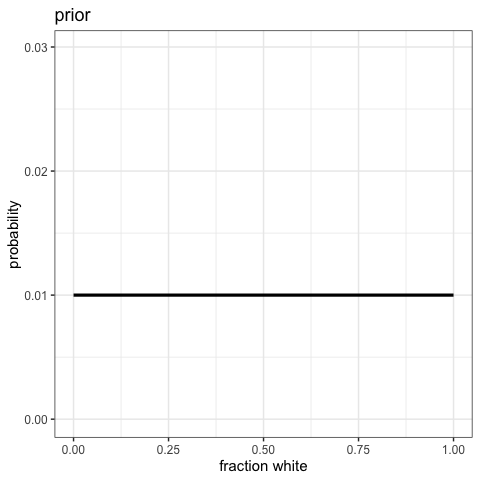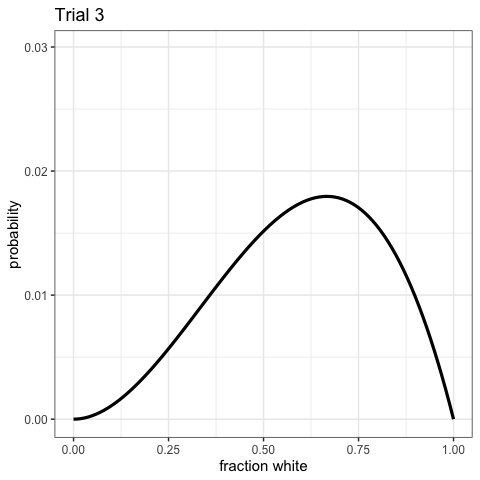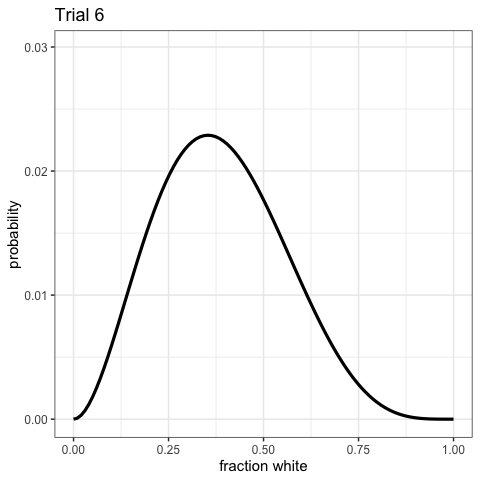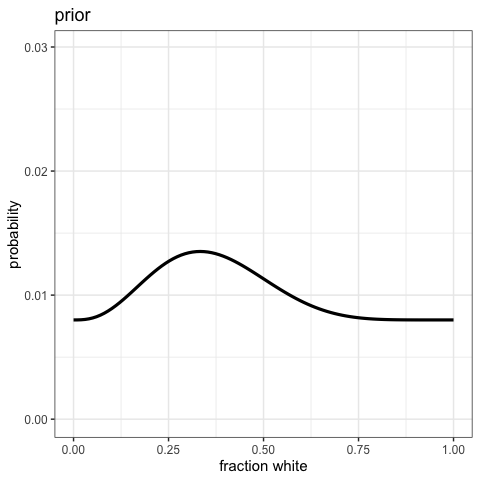
Visualize the posterior
